单元测试原则、实践与模式(五)
译者声明:本译文仅作为学习的记录,不作为任务商业用途,如有侵权请告知我删除。
本文禁止转载!
请支持原书正版:https://www.manning.com/books/unit-testing
第五章 模拟和测试脆弱性
Chapter 5 Mocks and test fragility
This chapter covers 本章内容涵盖
- Differentiating mocks from stubs 区分 mock 和 stubs
- Defining observable behavior and implementation details 定义可观察的行为和实现细节
- Understanding the relationship between mocks and test fragility 了解 mock 和测试脆弱性之间的关系
- Using mocks without compromising resistance to refactoring 在不影响抵御重构的情况下使用 mock
Chapter 4 introduced a frame of reference that you can use to analyze specific tests and unit testing approaches. In this chapter, you’ll see that frame of reference in action; we’ll use it to dissect the topic of mocks.
第 4 章介绍了一个参考框架,你可以用它来分析特定的测试和单元测试方法。在本章中,你将看到这个参考框架的作用;我们将用它来剖析 mocks 这个主题。
The use of mocks in tests is a controversial subject. Some people argue that mocks are a great tool and apply them in most of their tests. Others claim that mocks lead to test fragility and try not to use them at all. As the saying goes, the truth lies somewhere in between. In this chapter, I’ll show that, indeed, mocks often result in fragile tests—tests that lack the metric of resistance to refactoring. But there are still cases where mocking is applicable and even preferable.
在测试中使用 mocks 是一个有争议的话题。有些人认为,mocks 是一个很好的工具,并在他们的大多数测试中使用。另一些人则声称,mocks 会导致测试的脆弱性,并试图不使用它们。俗话说,真理就在两者之间。在这一章中,我将表明,的确,mocks 经常导致脆弱的测试–缺乏抵御重构的指标的测试。但仍有一些情况下,mocks 是适用的,甚至是可取的。
This chapter draws heavily on the discussion about the London versus classical schools of unit testing from chapter 2. In short, the disagreement between the schools stems from their views on the test isolation issue. The London school advocates isolating pieces of code under test from each other and using test doubles for all but immutable dependencies to perform such isolation.
本章在很大程度上借鉴了第二章中关于单元测试的伦敦学派和经典学派的讨论。简而言之,这些学派之间的分歧源于他们对测试隔离问题的看法。伦敦学派主张将被测试的代码片断相互隔离,除了不可更改的依赖外,其他的都使用测试替身来执行这种隔离。
The classical school stands for isolating unit tests themselves so that they can be run in parallel. This school uses test doubles only for dependencies that are shared between tests.
经典学派主张隔离单元测试本身,以便它们可以并行运行。这个学派只对测试之间共享的依赖使用测试替身。
There’s a deep and almost inevitable connection between mocks and test fragility. In the next several sections, I will gradually lay down the foundation for you to see why that connection exists. You will also learn how to use mocks so that they don’t compromise a test’s resistance to refactoring.
在 mocks 和测试的脆弱性之间有一个深刻的、几乎不可避免的关联。在接下来的几节中,我将逐步为你打下基础,让你了解为什么会有这种关联。你还将学习如何使用 mock,使其不影响测试抵御重构。
5.1 区分 Mock 和 Stub
Differentiating mocks from stubs
In chapter 2, I briefly mentioned that a mock is a test double that allows you to examine interactions between the system under test (SUT) and its collaborators. There’s another type of test double: a stub. Let’s take a closer look at what a mock is and how it is different from a stub.
在第二章中,我简要地提到,mock 是一种测试替身,它允许你检查被测系统(SUT)和它的合作者之间的交互。还有另一种类型的测试替身:stub。让我们仔细看看什么是 mock,以及它与 stub 有什么不同。
译者注:Mock 一般翻译为模拟,而 Stub 一般翻译为存根或桩。
5.1.1 测试替身的类型
The types of test doubles
A test double is an overarching term that describes all kinds of non-production-ready, fake dependencies in tests. The term comes from the notion of a stunt double in a movie. The major use of test doubles is to facilitate testing; they are passed to the system under test instead of real dependencies, which could be hard to set up or maintain.
测试替身是一个总称,它描述了测试中所有的非生产就绪的、虚假的依赖。这个术语来自于电影中特技替身的概念。测试替身的主要用途是促进测试;它们被传递给被测系统,而不是真正的依赖,后者可能很难设置或维护。
According to Gerard Meszaros, there are five variations of test doubles: dummy, stub, spy, mock, and fake. Such a variety can look intimidating, but in reality, they can all be grouped together into just two types: mocks and stubs (figure 5.1).
根据 Gerard Meszaros 的说法,测试替身有五种变化:dummy、stub、spy、mock 和 fake。这样的种类看起来很吓人,但实际上,它们都可以归纳为两种类型:mocks 和 stubs(图5.1)。
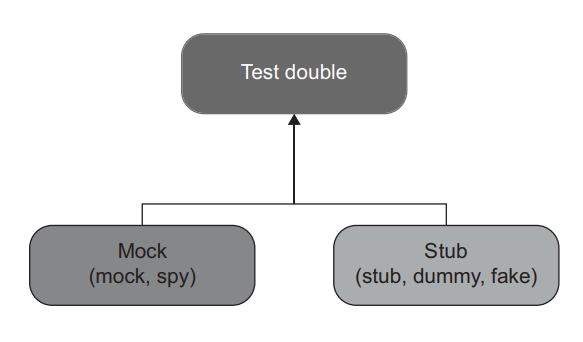
Figure 5.1 All variations of test doubles can be categorized into two types: mocks and stubs. 图5.1 所有测试替身的变化都可以归为两种类型:mocks 和 stubs。
The difference between these two types boils down to the following: 这两种类型的区别可归结为以下几点:
Mocks help to emulate and examine outcoming interactions. These interactions are calls the SUT makes to its dependencies to change their state.
Mocks 有助于模拟和检查传出的交互。这些交互是 SUT 对其依赖的调用,以改变它们的状态。
Stubs help to emulate incoming interactions. These interactions are calls the SUT makes to its dependencies to get input data (figure 5.2).
Stubs 有助于模拟传入的交互。这些交互是 SUT 对其依赖的调用,以获得输入数据(图5.2)。
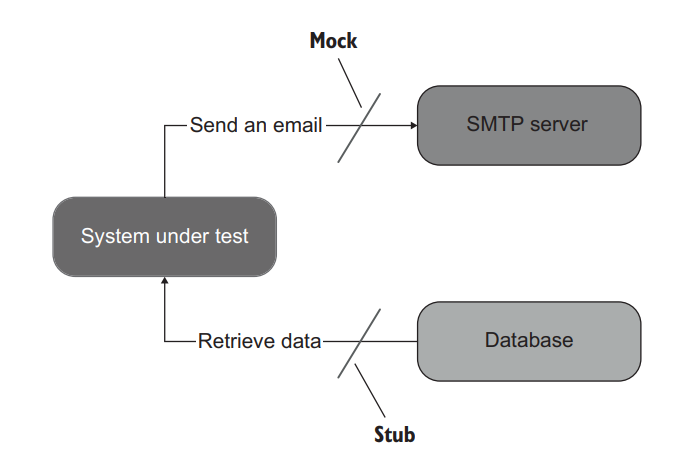
Figure 5.2 Sending an email is an outcoming interaction: an interaction that results in a side effect in the SMTP server. A test double emulating such an interaction is a mock. Retrieving data from the database is an incoming interaction; it doesn’t result in a side effect. The corresponding test double is a stub. 图5.2 发送电子邮件是一个传出的交互:一个使 SMTP 服务器产生副作用的交互。模拟这种交互的测试替身是一个 mock。从数据库中检索数据是一个传入交互;它不会导致副作用。相应的测试替身是一个 stub。
译者注
模拟对象(Mock):模拟对象对于将要进行的调用存在明确的预期。它会根据预先编排好的答案响应所有的调用。如果接收的调用不满足预期,它们会抛出异常。通常使用模拟对象时,会在最终的验证过程中进行检查,以确保它们接收到符合预期的所有调用。
间谍对象(Spy):间谍对象是一种特殊的存根对象。除了响应某些具体方法之外,它还会根据测试的调用,记录一些信息。比如,使用间谍对象进行测试,它可能会记录某个方法一共被调用了多少次等等;
对 Spy 的分类貌似并没有一致的标准
存根对象(Stub):为测试过程中调用的方法提供预先准备好的答案,但通常不会对测试调用之外的方法有任何响应。与假实现不同,存根只满足于特定的场景,而无法看作是一个可用的实现;
哑对象(Dummy Object):哑对象不会被实际使用,通常它们只是用来填充参数列表。它们可以是简单的占位符,只是为了满足方法签名的需求;例如我们调用一个 Test Double 对象的一个方法, 这个方法需要传递几个参数, 但是其中某个参数无论是什么值都不会影响测试的结果, 那么这个参数就是一个 Dummy object.
假实现(Fake Object):假实现是一种实际可以使用的特定实现,但跟真实实现相比会简化很多。一般不会用于生产环境。比如,内存数据库就是一个很好的例子,对于绝大多数场景,它提供的功能已经足够了,但是不会被用于生产环境;
All other differences between the five variations are insignificant implementation details. For example, spies serve the same role as mocks. The distinction is that spies are written manually, whereas mocks are created with the help of a mocking framework. Sometimes people refer to spies as handwritten mocks.
这五种变化之间的所有其他差异都是无关紧要的实现细节。例如,spies 的作用与 mocks 相同。区别在于,spies 是手动编写的,而mocks 是在 mocking 框架的帮助下创建的。有时人们会把 spies 称为手写的 mock。
On the other hand, the difference between a stub, a dummy, and a fake is in how intelligent they are. A dummy is a simple, hardcoded value such as a null value or a made-up string. It’s used to satisfy the SUT’s method signature and doesn’t participate in producing the final outcome. A stub is more sophisticated. It’s a fully fledged dependency that you configure to return different values for different scenarios. Finally, a fake is the same as a stub for most purposes. The difference is in the rationale for its creation: a fake is usually implemented to replace a dependency that doesn’t yet exist.
另一方面,stub、dummy 和 fake之间的区别在于它们的智能程度。一个 dummy 是一个简单的、硬编码的值,比如一个空值或一个捏造的字符串。它被用来满足 SUT 的方法签名,不参与产生最终结果。stub 是更复杂的。它是一个完全成熟的依赖,你可以配置它来为不同的场景返回不同的值。最后,在大多数情况下,fake 和 stub 是一样的。区别在于创建它的理由:fake 通常是为了替换一个尚不存在的依赖。
Notice the difference between mocks and stubs (aside from outcoming versus incoming interactions). Mocks help to emulate and examine interactions between the SUT and its dependencies, while stubs only help to emulate those interactions. This is an important distinction. You will see why shortly.
注意 mocks 和 stubs 之间的区别(除了传出与传入的交互)。Mocks 有助于模拟和检查 SUT 和它的依赖之间的交互,而 stubs 只有助于模拟这些交互。这是一个重要的区别。你很快就会看到原因。
5.1.2 Mock(工具)vs. Mock(测试替身)
Mock (the tool) vs. mock (the test double)
The term mock is overloaded and can mean different things in different circumstances. I mentioned in chapter 2 that people often use this term to mean any test double, whereas mocks are only a subset of test doubles. But there’s another meaning for the term mock. You can refer to the classes from mocking libraries as mocks, too. These classes help you create actual mocks, but they themselves are not mocks per se. The following listing shows an example.
mock 这个词是重载的,在不同的情况下可以有不同的含义。我在第 2 章中提到,人们经常用这个词来指任何测试用的替身,而 mock 只是测试用替身的一个子集。但是 mock 这个术语还有另一种含义。你也可以把 mocking 库中的类称为 mock。这些类可以帮助你创建实际的 mock,但它们本身并不是 mock。下面的清单显示了一个例子。
Listing 5.1 Using the Mock class from a mocking library to create a mock 使用 mocking 库中的 Mock 类创建 mock
1 | [] |
The test in listing 5.1 uses the Mock class from the mocking library of my choice (Moq). This class is a tool that enables you to create a test double—a mock. In other words, the class Mock (or Mock) is a mock (the tool), while the instance of that class, mock, is a mock (the test double). It’s important not to conflate a mock (the tool) with a mock (the test double) because you can use a mock (the tool) to create both types of test doubles: mocks and stubs.
列表 5.1 中的测试使用了我选择的 mocking 库(Moq)中的 Mock 类。这个类是一个工具,使你能够创建一个测试替身:一个 mock。换句话说,Mock(或Mock)类是一个 mock(工具),而该类的实例,mock,是一个 mock(测试用的替身)。重要的是不要把 mock(工具)和 mock(测试替身)混为一谈,因为你可以使用 mock(工具)来创建两种类型的测试替身:mocks 和 stubs。
The test in the following listing also uses the Mock class, but the instance of that class is not a mock, it’s a stub.
下面列表中的测试也使用了 Mock 类,但该类的实例不是一个 mock,而是一个 stub。
Listing 5.2 Using the Mock class to create a stub 使用 Mock 类创建stub
1 | [] |
This test double emulates an incoming interaction—a call that provides the SUT with input data. On the other hand, in the previous example (listing 5.1), the call to SendGreetingsEmail() is an outcoming interaction. Its sole purpose is to incur a side effect—send an email.
这个测试替身模拟了一个传入的交互–为 SUT 提供输入数据的调用。另一方面,在前面的例子中(清单 5.1),对 SendGreetingsEmail() 的调用是一个传出交互。它的唯一目的是产生一个副作用–发送一封电子邮件。
5.1.3 不要断言与 stubs 的交互
Don’t assert interactions with stubs
As I mentioned in section 5.1.1, mocks help to emulate and examine outcoming interactions between the SUT and its dependencies, while stubs only help to emulate incoming interactions, not examine them. The difference between the two stems from the guideline of never asserting interactions with stubs. A call from the SUT to a stub is not part of the end result the SUT produces. Such a call is only a means to produce the end result: a stub provides input from which the SUT then generates the output.
正如我在第 5.1.1 节中提到的,mocks 有助于模拟和检查 SUT 和其依赖之间的传出交互,而 stubs 只有助于模拟传入交互,而不是检查它们。两者之间的区别来自于永不断言与 stubs 的交互的准则。从 SUT 到 stub 的调用不是 SUT 产生的最终结果的一部分。这种调用只是产生最终结果的一种手段:stub 提供输入,然后由 SUT 产生输出。
NOTE
Asserting interactions with stubs is a common anti-pattern that leads to fragile tests.
断言与 stubs 的交互是一种常见的反模式,会导致脆弱的测试。
As you might remember from chapter 4, the only way to avoid false positives and thus improve resistance to refactoring in tests is to make those tests verify the end result (which, ideally, should be meaningful to a non-programmer), not implementation details. In listing 5.1, the check
正如你在第 4 章中所记得的,避免假阳性的唯一方法是使这些测试验证最终结果(最好是对非程序员有意义),而不是实现细节。在列表 5.1 中,检查
1 | mock.Verify(x => x.SendGreetingsEmail("user@email.com")) |
corresponds to an actual outcome, and that outcome is meaningful to a domain expert: sending a greetings email is something business people would want the system to do. At the same time, the call to GetNumberOfUsers() in listing 5.2 is not an outcome at all. It’s an internal implementation detail regarding how the SUT gathers data necessary for the report creation. Therefore, asserting this call would lead to test fragility: it shouldn’t matter how the SUT generates the end result, as long as that result is correct. The following listing shows an example of such a brittle test.
对应于一个实际的结果,而这个结果对领域专家来说是有意义的:发送问候邮件是商务人士希望系统做的事情。同时,列表 5.2 中对 GetNumberOfUsers() 的调用根本就不是一个结果。这是一个关于 SUT 如何收集创建报告所需数据的内部实现细节。因此,断言这个调用会导致测试的脆弱性:只要结果是正确的,SUT 如何生成最终结果就不重要。下面的列表显示了这样一个脆性测试的例子。
Listing 5.3 Asserting an interaction with a stub 断言与 stub 的交互
1 | [] |
This practice of verifying things that aren’t part of the end result is also called overspecification. Most commonly, overspecification takes place when examining interactions. Checking for interactions with stubs is a flaw that’s quite easy to spot because tests shouldn’t check for any interactions with stubs. Mocks are a more complicated subject: not all uses of mocks lead to test fragility, but a lot of them do. You’ll see why later in this chapter.
这种对不属于最终结果的东西进行验证的做法也被称为过度规范化。最常见的是,过度规范化发生在检查交互的时候。检查与 stub 的交互是一个很容易发现的缺陷,因为测试不应该检查与 stub 的任何交互。Mocks 是一个更复杂的问题:不是所有的 mocks 的使用都会导致脆弱的测试,但很多都会。你会在本章后面看到原因。
5.1.4 同时使用 mocks 和 stubs
Using mocks and stubs together
Sometimes you need to create a test double that exhibits the properties of both a mock and a stub. For example, here’s a test from chapter 2 that I used to illustrate the London style of unit testing.
有时你需要创建一个测试替身,它同时表现出 mock 和 stub 的特性。例如,这里是第 2 章的一个测试,我用它来说明单元测试的伦敦风格。
Listing 5.4 storeMock: both a mock and a stub
1 | [] |
This test uses storeMock for two purposes: it returns a canned answer and verifies a method call made by the SUT. Notice, though, that these are two different methods: the test sets up the answer from HasEnoughInventory() but then verifies the call to RemoveInventory(). Thus, the rule of not asserting interactions with stubs is not violated here.
这个测试将 storeMock 用于两个目的:它返回一个预设的答案并验证 SUT 的方法调用。但请注意,这是两个不同的方法:测试从 HasEnoughInventory() 设置了答案,但随后检查了对 RemoveInventory() 的调用。因此,这里没有违反不断言与 stub 交互的规则。
When a test double is both a mock and a stub, it’s still called a mock, not a stub. That’s mostly the case because we need to pick one name, but also because being a mock is a more important fact than being a stub.
当一个测试替身既是一个 mock 又是一个 stub 时,它仍然被称为一个 mock,而不是一个 stub。这主要是因为我们需要选择一个名字,但也因为作为一个 mock是比作为一个 stub 更重要的事实。
5.1.5 mocks 和 stubs 如何与命令和查询相关
How mocks and stubs relate to commands and queries
The notions of mocks and stubs tie to the command query separation (CQS) principle. The CQS principle states that every method should be either a command or a query, but not both. As shown in figure 5.3, commands are methods that produce side effects and don’t return any value (return void). Examples of side effects include mutating an object’s state, changing a file in the file system, and so on. Queries are the opposite of that—they are side-effect free and return a value.
mocks 和 stubs 的概念与命令查询分离(CQS)原则有关。CQS 原则指出,每个方法要么是命令,要么是查询,但不能两者都是。如图 5.3 所示,命令是产生副作用且不返回任何值的方法(返回 void)。副作用的例子包括改变一个对象的状态,改变文件系统中的一个文件,等等。查询则与此相反–它们没有副作用,并返回一个值。
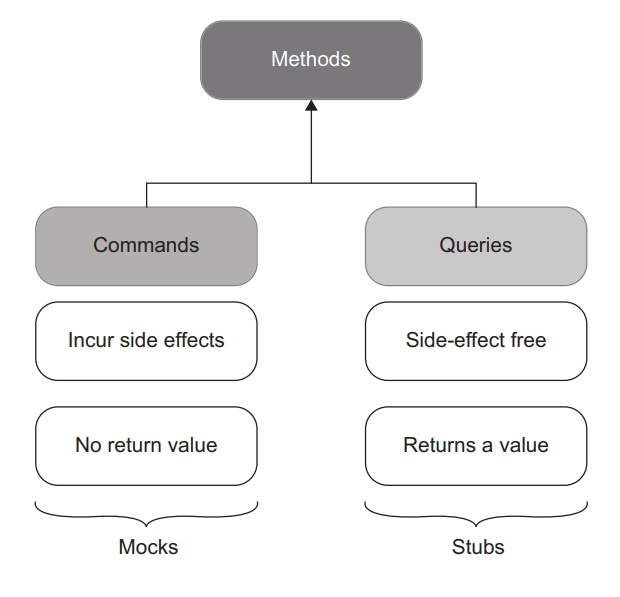
Figure 5.3 In the command query separation (CQS) principle, commands correspond to mocks, while queries are consistent with stubs. 图5.3 CQS (command query separation)原则中,命令对应 mocks,查询对应 stubs。
To follow this principle, be sure that if a method produces a side effect, that method’s return type is void. And if the method returns a value, it must stay side-effect free. In other words, asking a question should not change the answer. Code that maintains such a clear separation becomes easier to read. You can tell what a method does just by looking at its signature, without diving into its implementation details.
要遵循这一原则,就必须确保如果一个方法产生了副作用,那么该方法的返回类型就是 void。如果方法返回一个值,则必须保持无副作用。换句话说,提问不应改变答案。保持这种清晰分离的代码更容易阅读。只需查看方法的签名,就能知道该方法的作用,而无需深入研究其实现细节。
Of course, it’s not always possible to follow the CQS principle. There are always methods for which it makes sense to both incur a side effect and return a value. A classical example is stack.Pop(). This method both removes a top element from the stack and returns it to the caller. Still, it’s a good idea to adhere to the CQS principle whenever you can.
当然,并不总是能够遵循 CQS 原则。总有一些方法既要产生副作用,又要返回一个值,这是有道理的。一个经典的例子是 stack.Pop()。这个方法既从堆栈中移除一个顶层元素,又将其返回给调用者。不过,只要有可能,坚持 CQS 原则也是一个好主意。
Test doubles that substitute commands become mocks. Similarly, test doubles that substitute queries are stubs. Look at the two tests from listings 5.1 and 5.2 again (I’m showing their relevant parts here):
替代命令的测试替身是 mocks。同样,替代查询的测试替身是 stubs。再看看列表 5.1 和 5.2 中的两个测试(我在这里展示了它们的相关部分):
1 | var mock = new Mock<IEmailGateway>(); |
SendGreetingsEmail() is a command whose side effect is sending an email. The test double that substitutes this command is a mock. On the other hand, GetNumberOfUsers() is a query that returns a value and doesn’t mutate the database state. The corresponding test double is a stub.
SendGreetingsEmail()是一个命令,其副作用是发送一封电子邮件。替换这个命令的测试替身是一个 mock。另一方面,GetNumberOfUsers()是一个查询,它返回一个值,并且不改变数据库的状态。相应的测试替身是一个 stub。
5.2 可观察行为vs.实现细节
Observable behavior vs. implementation details
Section 5.1 showed what a mock is. The next step on the way to explaining the connection between mocks and test fragility is diving into what causes such fragility.
第 5.1 节展示了什么是 mock。在解释 mock 和测试脆弱性之间的关联的过程中,下一步是深入研究导致这种脆弱性的原因。
As you might remember from chapter 4, test fragility corresponds to the second attribute of a good unit test: resistance to refactoring. (As a reminder, the four attributes are protection against regressions, resistance to refactoring, fast feedback, and maintainability.) The metric of resistance to refactoring is the most important because whether a unit test possesses this metric is mostly a binary choice. Thus, it’s good to max out this metric to the extent that the test still remains in the realm of unit testing and doesn’t transition to the category of end-to-end testing. The latter, despite being the best at resistance to refactoring, is generally much harder to maintain.
你可能还记得第四章,测试的脆弱性对应于一个好的单元测试的第二个属性:抵御重构。(作为提醒,这四个属性是防止回归、抵御重构、快速反馈和可维护性)。抵御重构的指标是最重要的,因为一个单元测试是否拥有这个指标主要是一个二元选择。因此,最好在测试仍然保持在单元测试范畴而不转变为端到端测试的情况下尽可能地将这个指标最大化。后者尽管在抵御重构方面做得最好,但通常更难维护。
In chapter 4, you also saw that the main reason tests deliver false positives (and thus fail at resistance to refactoring) is because they couple to the code’s implementation details. The only way to avoid such coupling is to verify the end result the code produces (its observable behavior) and distance tests from implementation details as much as possible. In other words, tests must focus on the whats, not the hows. So, what exactly is an implementation detail, and how is it different from an observable behavior?
在第 4 章中,你还看到,测试产生假阳性的主要原因(因为在抵御重构方面失败)是由于它们与代码的实现细节耦合。避免这种耦合的唯一方法是验证代码产生的最终结果(它的可观察行为),并尽可能地使测试远离实现细节。换句话说,测试必须专注于 whats(是什么),而不是 hows(怎么做)。那么,到底什么是实现细节,它与可观察行为有什么不同呢?
5.2.1 可观察行为与开放 API 不同
Observable behavior is not the same as a public API
All production code can be categorized along two dimensions: 所有的生产代码都可以沿着两个维度进行分类:
- Public API vs. private API (where API means application programming interface) 开放 API与私有 API(其中 API 指的是应用编程接口)
- Observable behavior vs. implementation details 可观察的行为与实现细节
The categories in these dimensions don’t overlap. A method can’t belong to both a public and a private API; it’s either one or the other. Similarly, the code is either an internal implementation detail or part of the system’s observable behavior, but not both.
这两个维度的类别是不重叠的。一个方法不能同时属于开放 API 和私有 API;它要么是这一个,要么是另一个。同样,代码要么是内部实现细节,要么是系统可观察行为的一部分,但不能两者兼得。
Most programming languages provide a simple mechanism to differentiate between the code base’s public and private APIs. For example, in C#, you can mark any member in a class with the private keyword, and that member will be hidden from the client code, becoming part of the class’s private API. The same is true for classes: you can easily make them private by using the private or internal keyword.
大多数编程语言提供了一个简单的机制来区分代码库的开放和私有 API。例如,在 C# 中,你可以用 private 关键字标记类中的任何成员,该成员将从客户端代码中隐藏,成为该类的私有 API 的一部分。对于类来说也是如此:你可以通过使用 private 或 internal 关键字轻松地使它们成为私有的。
The distinction between observable behavior and internal implementation details is more nuanced. For a piece of code to be part of the system’s observable behavior, it has to do one of the following things:
可观察的行为和内部实现细节之间的区别更加细微。要使一段代码成为系统可观察行为的一部分,它必须做以下事情之一:
- Expose an operation that helps the client achieve one of its goals. An operation is a method that performs a calculation or incurs a side effect or both. 暴露一个操作,帮助客户实现其目标之一。操作是一个执行计算或产生副作用的方法,或者两者都有。
- Expose a state that helps the client achieve one of its goals. State is the current condition of the system. 暴露一个状态,帮助客户实现其目标之一。状态是系统的当前状况。
Any code that does neither of these two things is an implementation detail.
任何不做这两件事的代码都是一个实现细节。
Notice that whether the code is observable behavior depends on who its client is and what the goals of that client are. In order to be a part of observable behavior, the code needs to have an immediate connection to at least one such goal. The word client can refer to different things depending on where the code resides. The common examples are client code from the same code base, an external application, or the user interface.
注意,代码是否是可观察的行为,取决于它的客户是谁,以及客户的目标是什么。为了成为可观察行为的一部分,代码需要与至少一个这样的目标有直接关联。客户端这个词可以指代不同的东西,这取决于代码所在的地方。常见的例子是来自同一代码库的客户端代码、外部应用程序或用户界面。
Ideally, the system’s public API surface should coincide with its observable behavior, and all its implementation details should be hidden from the eyes of the clients. Such a system has a well-designed API (figure 5.4).
理想情况下,系统的开放 API 接口应该与它的可观察行为相吻合,它的所有实现细节都应该从客户的眼中隐藏起来。这样的系统有一个精心设计的 API(图5.4)。
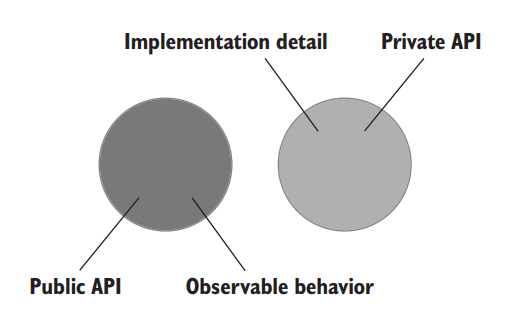
Figure 5.4 In a well-designed API, the observable behavior coincides with the public API, while all implementation details are hidden behind the private API. 图 5.4 在一个设计良好的 API 中,可观察的行为与开放 API 相吻合,而所有的实现细节都隐藏在私有 API 后面。
Often, though, the system’s public API extends beyond its observable behavior and starts exposing implementation details. Such a system’s implementation details leak to its public API surface (figure 5.5).
但通常情况下,系统的开放 API 会超出其可观察行为的范围,并开始暴露出实现细节。这样一个系统的实现细节就会泄露到它的开放 API 层(图5.5)。
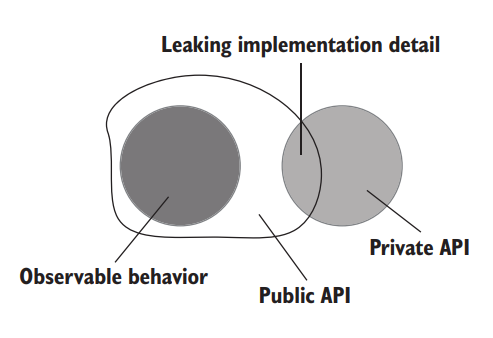
Figure 5.5 A system leaks implementation details when its public API extends beyond the observable behavior. 图 5.5 当系统开放 API 超出可观察行为时,系统会泄露实现细节。
5.2.2 泄漏实现细节:一个操作的示例
Leaking implementation details: An example with an operation
Let’s take a look at examples of code whose implementation details leak to the public API. Listing 5.5 shows a User class with a public API that consists of two members: a Name property and a NormalizeName() method. The class also has an invariant: users’ names must not exceed 50 characters and should be truncated otherwise.
让我们来看看那些实现细节泄露给公共 API 的代码例子。清单 5.5 显示了一个拥有开放 API 的用户类,它由两个成员组成:一个 Name 属性和一个NormalizeName() 方法。这个类也有一个不变量:用户的名字不能超过 50 个字符,否则应该被截断。
Listing 5.5 User class with leaking implementation details 具有泄漏实现详细信息的用户类
1 | public class User |
UserController is client code. It uses the User class in its RenameUser method. The goal of this method, as you have probably guessed, is to change a user’s name.
UserController 是客户端代码。它在其 RenameUser 方法中使用了 User 类。这个方法的目标,你可能已经猜到了,就是改变一个用户的名字。
So, why isn’t User’s API well-designed? Look at its members once again: the Name property and the NormalizeName method. Both of them are public. Therefore, in order for the class’s API to be well-designed, these members should be part of the observable behavior. This, in turn, requires them to do one of the following two things (which I’m repeating here for convenience):
那么,为什么用户 API 没有设计好呢?再次看一下它的成员:Name 属性和 NormalizeName 方法。它们都是开放的。因此,为了使类的 API 设计良好,这些成员应该是可观察行为的一部分。这又要求它们执行以下两种操作之一(为方便起见,我在此重复提及)
- Expose an operation that helps the client achieve one of its goals. 暴露一个操作,帮助客户实现其目标之一。
- Expose a state that helps the client achieve one of its goals. 暴露一个能帮助客户实现其目标之一的状态。
Only the Name property meets this requirement. It exposes a setter, which is an operation that allows UserController to achieve its goal of changing a user’s name. The NormalizeName method is also an operation, but it doesn’t have an immediate connection to the client’s goal. The only reason UserController calls this method is to satisfy the invariant of User. NormalizeName is therefore an implementation detail that leaks to the class’s public API (figure 5.6).
只有 Name 属性符合这一要求。它暴露了一个 setter,这是一个允许 UserController 实现其改变用户名字的目标的操作。NormalizeName 方法也是一个操作,但它与客户的目标没有直接联系。UserController 调用这个方法的唯一原因是为了满足 User 的不变量。因此,NormalizeName 是一个实现细节,它泄露给了该类的开放 API(图5.6)。
To fix the situation and make the class’s API well-designed, User needs to hide NormalizeName() and call it internally as part of the property’s setter without relying on the client code to do so. Listing 5.6 shows this approach.
为了解决这个问题,并使类的 API 得到良好的设计,User 需要隐藏 NormalizeName(),并在内部将其作为属性的 setter 的一部分来调用,而不依靠客户端代码来完成。清单 5.6 显示了这种方法。
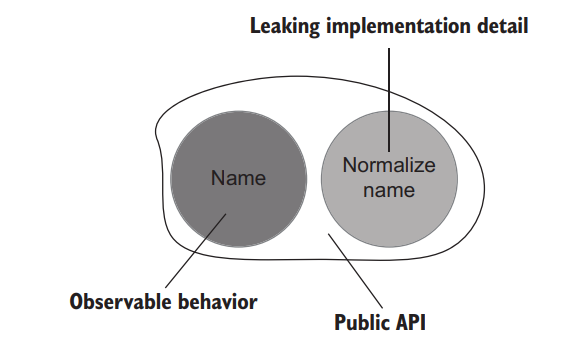
Figure 5.6 The API of User is not welldesigned: it exposes the NormalizeName method, which is not part of the observable behavior. 图 5.6 User 的 API 设计得不好:它暴露了 NormalizeName 方法,这不是可观察行为的一部分。
Listing 5.6 A version of User with a well-designed API 具有精心设计的 API 的 User 版本
1 | public class User |
User’s API in listing 5.6 is well-designed: only the observable behavior (the Name property) is made public, while the implementation details (the NormalizeName method) are hidden behind the private API (figure 5.7).
列表 5.6 中用户的 API 设计得很好:只有可观察的行为(Name属性)是公开的,而实现细节(NormalizeName方法)则隐藏在私有 API 后面(图5.7)。
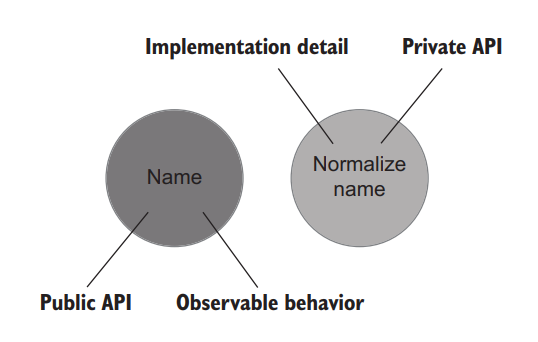
Figure 5.7 User with a well-designed API. Only the observable behavior is public; the implementation details are now private. 图 5.7 拥有精心设计的 API 的 User。 只有可观察的行为是公开的;实现的细节现在是私有的。
NOTE
Strictly speaking, Name’s getter should also be made private, because it’s not used by UserController. In reality, though, you almost always want to read back changes you make. Therefore, in a real project, there will certainly be another use case that requires seeing users’ current names via Name’s getter.
严格来说,Name 的 getter 也应该是私有的,因为它不被 UserController 使用。但在现实中,你几乎总是想读回你所做的改变。因此,在一个真实的项目中,肯定会有另一个用例需要通过 Name 的 getter 查看用户的当前姓名。
There’s a good rule of thumb that can help you determine whether a class leaks its implementation details. If the number of operations the client has to invoke on the class to achieve a single goal is greater than one, then that class is likely leaking implementation details. Ideally, any individual goal should be achieved with a single operation. In listing 5.5, for example, UserController has to use two operations from User:
有一个很好的经验法则,可以帮助你确定一个类是否泄露了它的实现细节。如果客户端为实现一个目标而在类上调用的操作数量大于 1,那么这个类就有可能泄露了实现细节。理想情况下,任何单独的目标都应该通过一个操作来实现。例如,在列表 5.5 中,UserController 必须使用 User 的两个操作:
1 | string normalizedName = user.NormalizeName(newName); |
After the refactoring, the number of operations has been reduced to one:
经过重构后,操作的数量减少到了一个:
1 | user.Name = newName; |
In my experience, this rule of thumb holds true for the vast majority of cases where business logic is involved. There could very well be exceptions, though. Still, be sure to examine each situation where your code violates this rule for a potential leak of implementation details.
根据我的经验,这个经验法则对绝大多数涉及业务逻辑的情况都是正确的。不过,很可能会有例外。但是,一定要检查你的代码违反这一规则的每一种情况,看看是否有实现细节的潜在泄漏。
5.2.3 精心设计的 API 和封装
Well-designed API and encapsulation
Maintaining a well-designed API relates to the notion of encapsulation. As you might recall from chapter 3, encapsulation is the act of protecting your code against inconsistencies, also known as invariant violations. An invariant is a condition that should be held true at all times. The User class from the previous example had one such invariant: no user could have a name that exceeded 50 characters.
保持一个精心设计的 API 与封装的概念有关。你可能还记得第三章的内容,封装是保护你的代码不受不一致的影响,也被称为违反不变量。不变量是一个在任何时候都应该保持真实的条件。前面例子中的 User 类有一个这样的不变量:任何用户的名字都不能超过 50 个字符。
Exposing implementation details goes hand in hand with invariant violations—the former often leads to the latter. Not only did the original version of User leak its implementation details, but it also didn’t maintain proper encapsulation. It allowed the client to bypass the invariant and assign a new name to a user without normalizing that name first.
暴露实现细节与违反不变量的行为是息息相关的–前者往往会导致后者的出现。User 的原始版本不仅泄露了它的实现细节,而且也没有保持适当的封装。它允许客户端绕过不变量,为用户分配一个新的名字,而不先将该名字规范化。
Encapsulation is crucial for code base maintainability in the long run. The reason why is complexity. Code complexity is one of the biggest challenges you’ll face in software development. The more complex the code base becomes, the harder it is to work with, which, in turn, results in slowing down development speed and increasing the number of bugs.
从长远来看,封装对于代码库的可维护性至关重要。其原因是复杂性。代码的复杂性是你在软件开发中所面临的最大挑战之一。代码库变得越复杂,就越难处理,这反过来又会导致开发速度减慢和错误数量增加。
Without encapsulation, you have no practical way to cope with ever-increasing code complexity. When the code’s API doesn’t guide you through what is and what isn’t allowed to be done with that code, you have to keep a lot of information in mind to make sure you don’t introduce inconsistencies with new code changes. This brings an additional mental burden to the process of programming. Remove as much of that burden from yourself as possible. You cannot trust yourself to do the right thing all the time—so, eliminate the very possibility of doing the wrong thing. The best way to do so is to maintain proper encapsulation so that your code base doesn’t even provide an option for you to do anything incorrectly. Encapsulation ultimately serves the same goal as unit testing: it enables sustainable growth of your software project.
没有封装,你就没有实用的方法来应对不断增加的代码复杂性。当代码的 API 没有指导你什么是可以做的,什么是不允许做的,你必须记住很多信息,以确保你不会在新的代码修改中引入不一致的地方。这给编程的过程带来了额外的心理负担。尽可能多地从自己身上消除这种负担。你不能相信自己总是做正确的事情,所以要消除做错事情的可能性。这样做的最好方法是保持适当的封装,这样你的代码库就不会为你提供一个做错事的选项。封装最终与单元测试的目标相同:它能使你的软件项目持续增长。
There’s a similar principle: tell-don’t-ask. It was coined by Martin Fowler (https:// martinfowler.com/bliki/TellDontAsk.html) and stands for bundling data with the functions that operate on that data. You can view this principle as a corollary to the practice of encapsulation. Code encapsulation is a goal, whereas bundling data and functions together, as well as hiding implementation details, are the means to achieve that goal:
还有一个类似的原则:[Tell-don’t-ask](https:// martinfowler.com/bliki/TellDontAsk.html)。它是由 [Martin Fowler](https:// martinfowler.com/bliki/TellDontAsk.html) 创造的,代表了将数据与操作该数据的函数捆绑在一起。你可以把这个原则看作是封装实践的一个推论。代码封装是一个目标,而将数据和函数捆绑在一起,以及隐藏实现细节,是实现这个目标的手段:
Hiding implementation details helps you remove the class’s internals from the eyes of its clients, so there’s less risk of corrupting those internals.
隐藏实现细节可以帮助你将类的内部结构从其客户的眼中移除,因此破坏这些内部结构的风险较小。
Bundling data and operations helps to make sure these operations don’t violate the class’s invariants.
捆绑数据和操作有助于确保这些操作不会违反类的不变量。
5.2.4 泄露实现细节:一个带有状态的示例
Leaking implementation details: An example with state
The example shown in listing 5.5 demonstrated an operation (the NormalizeName method) that was an implementation detail leaking to the public API. Let’s also look at an example with state. The following listing contains the MessageRenderer class you saw in chapter 4. It uses a collection of sub-renderers to generate an HTML representation of a message containing a header, a body, and a footer.
列表 5.5 中的例子展示了一个操作(NormalizeName 方法),这是一个泄露给开放 API 的实现细节。我们也来看看一个有状态的例子。下面的列表包含了你在第4 章看到的 MessageRenderer 类。它使用一个子渲染器的集合来生成一个包含标题、正文和页脚的 HTML 格式的消息。
Listing 5.7 State as an implementation detail 状态作为实现细节
1 | public class MessageRenderer : IRenderer |
The sub-renderers collection is public. But is it part of observable behavior? Assuming that the client’s goal is to render an HTML message, the answer is no. The only class member such a client would need is the Render method itself. Thus SubRenderers is also a leaking implementation detail.
sub-renderers 的集合是公开的。但它是可观察行为的一部分吗?假设客户端的目标是渲染一条 HTML 消息,答案是否定的。这样的客户端唯一需要的类成员是 Render 方法本身。因此,SubRenderers 也是一个泄露的实现细节。
I bring up this example again for a reason. As you may remember, I used it to illustrate a brittle test. That test was brittle precisely because it was tied to this implementation detail—it checked to see the collection’s composition. The brittleness was fixed by re-targeting the test at the Render method. The new version of the test verified the resulting message—the only output the client code cared about, the observable behavior.
我再次提出这个例子是有原因的。你可能还记得,我用它来说明一个脆弱的测试。那个测试之所以脆弱,正是因为它与这个实现细节有关–它检查了集合的组成。通过在 Render 方法上重新定位测试,脆弱性得到了解决。新版本的测试验证了结果信息–客户代码关心的唯一输出,即可观察的行为。
As you can see, there’s an intrinsic connection between good unit tests and a welldesigned API. By making all implementation details private, you leave your tests no choice other than to verify the code’s observable behavior, which automatically improves their resistance to refactoring.
正如你所看到的,在良好的单元测试和精心设计的 API 之间存在着内在的联系。通过使所有的实现细节私有化,你让你的测试别无选择,只能验证代码的可观察行为,这将自动提高他们抵御重构的能力。
TIP
Making the API well-designed automatically improves unit tests.
将 API 设计得很好会自动改善单元测试。
Another guideline flows from the definition of a well-designed API: you should expose the absolute minimum number of operations and state. Only code that directly helps clients achieve their goals should be made public. Everything else is implementation details and thus must be hidden behind the private API.
从精心设计的 API 的定义中可以看出:你应该开放出绝对最少数量的操作和状态。只有那些直接帮助客户实现其目标的代码才应该被开放。其他的都是实现细节,因此必须隐藏在私有 API 后面。
Note that there’s no such problem as leaking observable behavior, which would be symmetric to the problem of leaking implementation details. While you can expose an implementation detail (a method or a class that is not supposed to be used by the client), you can’t hide an observable behavior. Such a method or class would no longer have an immediate connection to the client goals, because the client wouldn’t be able to directly use it anymore. Thus, by definition, this code would cease to be part of observable behavior. Table 5.1 sums it all up.
请注意,不存在泄露可观察行为这样的问题,这与泄露实现细节的问题是相对的。虽然你可以暴露一个实现细节(一个不应该被客户端使用的方法或类),但你不能隐藏一个可观察的行为。这样的方法或类将不再与客户端的目标有直接的关联,因为客户端将不能再直接使用它。因此,根据定义,这段代码将不再是可观察行为的一部分。表 5.1 总结了这一切。
Table 5.1 The relationship between the code’s publicity and purpose. Avoid making implementation details public. 表5.1 代码的公开性与目的之间的关系。避免公开实现细节。
| Observable behavior | Implementation detail | |
|---|---|---|
| Public | Good | Bad |
| Private | N/A | Good |
5.3 mocks 和测试脆弱性之间的关系
The relationship between mocks and test fragility
The previous sections defined a mock and showed the difference between observable behavior and an implementation detail. In this section, you will learn about hexagonal architecture, the difference between internal and external communications, and (finally!) the relationship between mocks and test fragility.
前几节定义了 mock,并展示了可观察行为和实现细节之间的区别。在这一节中,你将了解到六边形架构,内部和外部通信的区别,以及(最后!)mocks 和测试脆弱性之间的关系。
5.3.1 定义六边形架构
Defining hexagonal architecture
A typical application consists of two layers, domain and application services, as shown in figure 5.8. The domain layer resides in the middle of the diagram because it’s the central part of your application. It contains the business logic: the essential functionality your application is built for. The domain layer and its business logic differentiate this application from others and provide a competitive advantage for the organization.
一个典型的应用程序由两层组成,领域和应用服务,如图 5.8 所示。领域层位于图的中间,因为它是应用程序的中心部分。它包含了业务逻辑:你的应用程序所建立的基本功能。领域层和它的业务逻辑使这个应用程序与其他的应用程序不同,并为组织提供竞争优势。
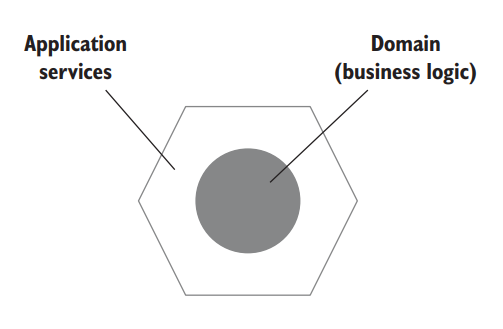
Figure 5.8 A typical application consists of a domain layer and an application services layer. The domain layer contains the application’s business logic; application services tie that logic to business use cases. 图 5.8 一个典型的应用程序包括一个领域层和一个应用服务层。 领域层包含应用程序的业务逻辑;应用服务将该逻辑与业务用例关联起来。
The application services layer sits on top of the domain layer and orchestrates communication between that layer and the external world. For example, if your application is a RESTful API, all requests to this API hit the application services layer first. This layer then coordinates the work between domain classes and out-of-process dependencies. Here’s an example of such coordination for the application service. It does the following:
应用服务层位于领域层之上,协调该层与外部世界的通信。例如,如果你的应用程序是一个 RESTful API,那么所有对这个 API 的请求都会首先进入应用服务层。然后,这一层协调领域类和进程外依赖之间的工作。下面是应用服务的这种协调的一个例子。它做了以下工作:
- Queries the database and uses the data to materialize a domain class instance 查询数据库并使用数据来初始化一个领域类实例
- Invokes an operation on that instance 在该实例上调用一个操作
- Saves the results back to the database 将结果保存到数据库中
The combination of the application services layer and the domain layer forms a hexagon, which itself represents your application. It can interact with other applications, which are represented with their own hexagons (see figure 5.9). These other applications could be an SMTP service, a third-party system, a message bus, and so on. A set of interacting hexagons makes up a hexagonal architecture.
应用服务层和领域层的结合形成了一个六边形,它本身代表了你的应用。它可以与其他应用交互,这些应用用它们自己的六边形表示(见图 5.9)。这些其他应用可以是 SMTP 服务、第三方系统、消息总线等等。一组相互作用的六边形构成了一个六边形的架构。
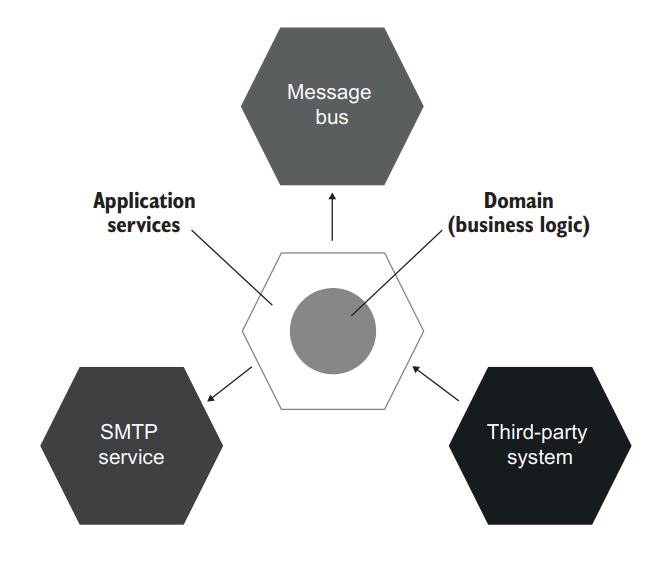
Figure 5.9 A hexagonal architecture is a set of interacting applications— hexagons. 图 5.9 六边形架构是一组相互作用的应用程序–六边形。
The term hexagonal architecture was introduced by Alistair Cockburn. Its purpose is to emphasize three important guidelines:
六边形架构这个术语是由 Alistair Cockburn 提出的。它的目的是为了强调三个重要的准则:
The separation of concerns between the domain and application services layers—Business logic is the most important part of the application. Therefore, the domain layer should be accountable only for that business logic and exempted from all other responsibilities. Those responsibilities, such as communicating with external applications and retrieving data from the database, must be attributed to application services. Conversely, the application services shouldn’t contain any business logic. Their responsibility is to adapt the domain layer by translating the incoming requests into operations on domain classes and then persisting the results or returning them back to the caller. You can view the domain layer as a collection of the application’s domain knowledge (how-to’s) and the application services layer as a set of business use cases (what-to’s).
领域层和应用服务层之间的关注点分离–业务逻辑是应用中最重要的部分。因此,领域层应该只对该业务逻辑负责,并免除所有其他责任。那些责任,如与外部应用程序通信和从数据库中检索数据,必须归于应用服务。反之,应用服务不应该包含任何业务逻辑。它们的职责是通过将传入的请求转化为对领域类的操作,然后将结果持久化或返回给调用者来适应领域层。你可以把领域层看作是应用程序领域知识的集合(how-to’s),把应用服务层看作是业务用例的集合(what-to’s)。
Communications inside your application—Hexagonal architecture prescribes a one-way flow of dependencies: from the application services layer to the domain layer. Classes inside the domain layer should only depend on each other; they should not depend on classes from the application services layer. This guideline flows from the previous one. The separation of concerns between the application services layer and the domain layer means that the former knows about the latter, but the opposite is not true. The domain layer should be fully isolated from the external world.
应用内部的通信–六边形架构规定了依赖的单向流动:从应用服务层到领域层。领域层内的类应该只相互依赖,它们不应该依赖应用服务层的类。这条准则源于前一条准则。应用服务层和领域层之间的关注点分离意味着前者知道后者,但反过来就不是这样了。领域层应该与外部世界完全隔离。
Communications between applications—External applications connect to your application through a common interface maintained by the application services layer. No one has a direct access to the domain layer. Each side in a hexagon represents a connection into or out of the application. Note that although a hexagon has six sides, it doesn’t mean your application can only connect to six other applications. The number of connections is arbitrary. The point is that there can be many such connections.
应用程序之间的通信-外部应用程序通过应用服务层维护的公共接口连接到你的应用程序。没有人可以直接访问领域层。六边形中的每一条边都代表进入或离开应用程序的连接。请注意,虽然一个六边形有六个面,但这并不意味着你的应用程序只能连接到其他六个应用程序。连接的数量是任意的。关键是可以有很多这样的连接。
Each layer of your application exhibits observable behavior and contains its own set of implementation details. For example, observable behavior of the domain layer is the sum of this layer’s operations and state that helps the application service layer achieve at least one of its goals. The principles of a well-designed API have a fractal nature: they apply equally to as much as a whole layer or as little as a single class.
你的应用程序的每一层都表现出可观察的行为,并包含它自己的一套实现细节。例如,领域层的可观察行为是该层的操作和状态的总和,帮助应用服务层实现至少一个目标。设计良好的API的原则具有分形的性质:它们同样适用于多至整个层或少至单个类。
When you make each layer’s API well-designed (that is, hide its implementation details), your tests also start to have a fractal structure; they verify behavior that helps achieve the same goals but at different levels. A test covering an application service checks to see how this service attains an overarching, coarse-grained goal posed by the external client. At the same time, a test working with a domain class verifies a subgoal that is part of that greater goal (figure 5.10).
当你把每一层的API设计得很好时(也就是说,隐藏其实现细节),你的测试也开始具有分形结构;它们验证有助于实现相同目标的行为,但在不同的层次。覆盖应用服务的测试检查该服务如何实现外部客户提出的总体的、粗略的目标。同时,与领域类一起工作的测试会验证作为该更大目标一部分的子目标(图5.10)。
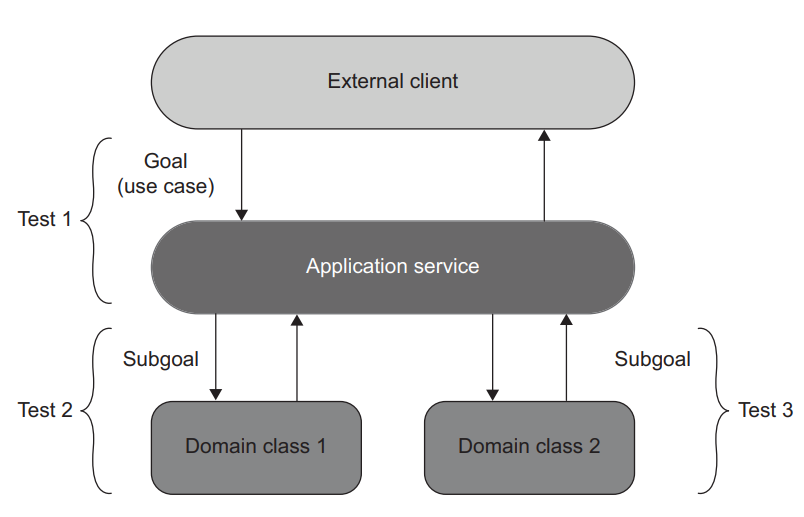
Figure 5.10 Tests working with different layers have a fractal nature: they verify the same behavior at different levels. A test of an application service checks to see how the overall business use case is executed. A test working with a domain class verifies an intermediate subgoal on the way to use-case completion. 图 5.10 在不同层工作的测试具有分形的性质:它们在不同层次上验证相同的行为。一个应用服务的测试检查整个业务用例是如何执行的。对一个领域类的测试验证了在完成用例过程中的一个中间子目标。
You might remember from previous chapters how I mentioned that you should be able to trace any test back to a particular business requirement. Each test should tell a story that is meaningful to a domain expert, and if it doesn’t, that’s a strong indication that the test couples to implementation details and therefore is brittle. I hope now you can see why.
你可能还记得我在前几章中提到,你应该能够将任何测试追溯到一个特定的业务需求。每个测试都应该讲述一个对领域专家有意义的故事,如果不是这样,那就充分说明测试与实现细节相联系,因此是很脆弱的。我希望现在你能明白为什么。
Observable behavior flows inward from outer layers to the center. The overarching goal posed by the external client gets translated into subgoals achieved by individual domain classes. Each piece of observable behavior in the domain layer therefore preserves the connection to a particular business use case. You can trace this connection recursively from the innermost (domain) layer outward to the application services layer and then to the needs of the external client. This traceability follows from the definition of observable behavior. For a piece of code to be part of observable behavior, it needs to help the client achieve one of its goals. For a domain class, the client is an application service; for the application service, it’s the external client itself.
可观察的行为从外层向内流向中心。由外部客户提出的总体目标被转化为由各个领域类实现的子目标。因此,领域层中的每一块可观察行为都保留了与特定业务用例的联系。你可以从最内部的(领域)层向外追溯这种联系,到应用服务层,然后到外部客户的需求。这种可追溯性来自于可观察行为的定义。要使一段代码成为可观察行为的一部分,它需要帮助客户实现其目标之一。对于一个领域类来说,客户端是一个应用服务;对于应用服务来说,它是外部客户端本身。
Tests that verify a code base with a well-designed API also have a connection to business requirements because those tests tie to the observable behavior only. A good example is the User and UserController classes from listing 5.6 (I’m repeating the code here for convenience).
验证具有精心设计的 API 的代码库的测试也与业务需求有关联,因为这些测试只与可观察行为挂钩。一个很好的例子是清单 5.6 中的 User 和 UserController 类(为了方便起见,我在这里重复了代码)。
Listing 5.8 A domain class with an application service 具有应用服务的领域类
1 | public class User |
UserController in this example is an application service. Assuming that the external client doesn’t have a specific goal of normalizing user names, and all names are normalized solely due to restrictions from the application itself, the NormalizeName method in the User class can’t be traced to the client’s needs. Therefore, it’s an implementation detail and should be made private (we already did that earlier in this chapter). Moreover, tests shouldn’t check this method directly. They should verify it only as part of the class’s observable behavior—the Name property’s setter in this example.
本例中的 UserController 是一个应用服务。假设外部客户端没有规范化用户名的特定目标,所有的名字都是完全由于应用程序本身的限制而被规范化的,那么User 类中的 NormalizeName 方法就不能被追踪到客户端的需求。因此,这是一个实现细节,应该做成私有的(我们在本章前面已经做了)。此外,测试不应该直接检查这个方法。他们应该只把它作为类的可观察行为的一部分来验证–在这个例子中的 Name 属性的 setter。
This guideline of always tracing the code base’s public API to business requirements applies to the vast majority of domain classes and application services but less so to utility and infrastructure code. The individual problems such code solves are often too low-level and fine-grained and can’t be traced to a specific business use case.
这条总是将代码库的开放 API 追踪到业务需求的准则适用于绝大多数的领域类和应用服务,但对实用程序和基础设施代码则不那么适用。这类代码所解决的个别问题往往过于低级和精细,无法追踪到具体的业务用例。
5.3.2 系统内通信与系统间通信
Intra-system vs. inter-system communications
There are two types of communications in a typical application: intra-system and intersystem. Intra-system communications are communications between classes inside your application. Inter-system communications are when your application talks to other applications (figure 5.11).
在一个典型的应用程序中,有两种类型的通信:系统内和系统间。系统内通信是你的应用程序内部的类之间的通信。系统间通信是指你的应用程序与其他应用程序的对话(图 5.11)。
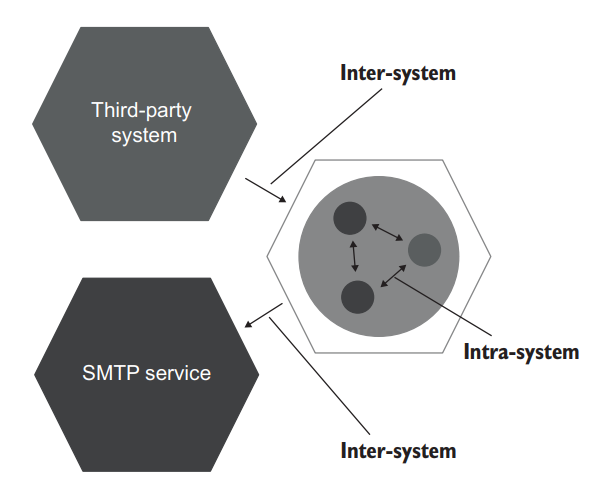
Figure 5.11 There are two types of communications: intra-system (between classes inside the application) and inter-system (between applications). 图5.11 有两种类型的通信:系统内(应用程序内部的类之间)和系统间(应用程序之间)。
NOTE
Intra-system communications are implementation details; inter-system communications are not.
系统内通信是实现细节;系统间通信则不是。
Intra-system communications are implementation details because the collaborations your domain classes go through in order to perform an operation are not part of their observable behavior. These collaborations don’t have an immediate connection to the client’s goal. Thus, coupling to such collaborations leads to fragile tests.
系统内通信是实现细节,因为你的领域类为了执行一个操作而进行的协作并不是它们可观察行为的一部分。这些协作与客户的目标没有直接关联。因此,与这种协作的耦合导致了脆弱的测试。
Inter-system communications are a different matter. Unlike collaborations between classes inside your application, the way your system talks to the external world forms the observable behavior of that system as a whole. It’s part of the contract your application must hold at all times (figure 5.12).
系统间的通信是一个不同的问题。与应用程序内部类之间的协作不同,你的系统与外部世界的对话方式形成了整个系统的可观察行为。它是你的应用程序在任何时候都必须持有的契约的一部分(图 5.12)。
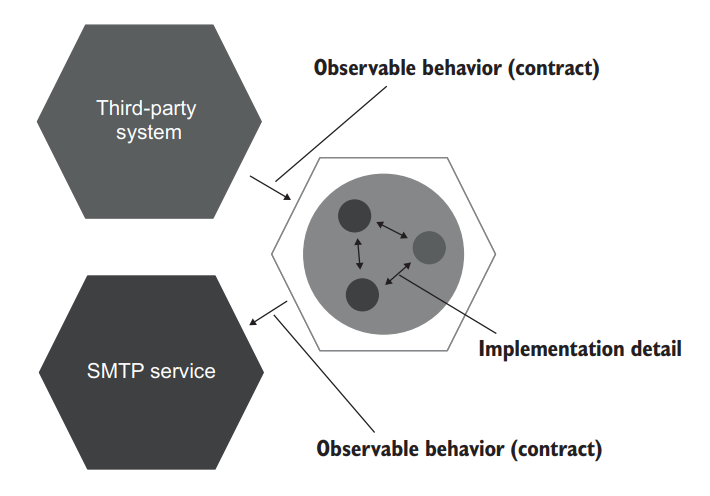
Figure 5.12 Inter-system communications form the observable behavior of your application as a whole. Intra-system communications are implementation details. 图 5.12 系统间通信构成了整个应用程序的可观察行为。系统内通信是实现细节。
This attribute of inter-system communications stems from the way separate applications evolve together. One of the main principles of such an evolution is maintaining backward compatibility. Regardless of the refactorings you perform inside your system, the communication pattern it uses to talk to external applications should always stay in place, so that external applications can understand it. For example, messages your application emits on a bus should preserve their structure, the calls issued to an SMTP service should have the same number and type of parameters, and so on.
系统间通信的这一属性源于独立的应用程序共同进化的方式。这种进化的主要原则之一是保持向后的兼容性。无论你在系统内部进行怎样的重构,它用来与外部应用程序对话的通信模式应该始终保持不变,以便外部应用程序能够理解它。例如,你的应用程序在总线上发出的消息应该保留其结构,对 SMTP 服务发出的调用应该有相同的参数数量和类型,等等。
The use of mocks is beneficial when verifying the communication pattern between your system and external applications. Conversely, using mocks to verify communications between classes inside your system results in tests that couple to implementation details and therefore fall short of the resistance-to-refactoring metric.
在验证你的系统和外部应用之间的通信模式时,使用 mock 是很有好处的。相反,使用模拟来验证系统内部类之间的通信,会导致测试与实现细节的耦合,因此不能达到抵御重构的指标。
5.3.3 系统内通信与系统间通信:示例
Intra-system vs. inter-system communications: An example
To illustrate the difference between intra-system and inter-system communications, I’ll expand on the example with the Customer and Store classes that I used in chapter 2 and earlier in this chapter. Imagine the following business use case:
为了说明系统内和系统间通信的区别,我将对我在第二章和本章前面使用的客户和商店类的例子进行扩展。想象一下下面这个业务用例:
A customer tries to purchase a product from a store. 一个客户试图从一个商店购买产品。
If the amount of the product in the store is sufficient, then 如果商店里的产品数量足够,那么
- – The inventory is removed from the store. 库存被从商店中移除。
- – An email receipt is sent to the customer. 一封电子邮件收据被发送给客户。
- – A confirmation is returned. 一个确认函被返回。
Let’s also assume that the application is an API with no user interface.
我们还假设该应用是一个没有用户界面的 API。
In the following listing, the CustomerController class is an application service that orchestrates the work between domain classes (Customer, Product, Store) and the external application (EmailGateway, which is a proxy to an SMTP service).
在下面的清单中,CustomerController 类是一个应用服务,它协调了领域类(Customer, Product, Store)和外部应用(EmailGateway,它是一个 SMTP 服务的代理)之间的工作。
Listing 5.9 Connecting the domain model with external applications 清单 5.9 将领域模型与外部应用程序连接起来
1 | public class CustomerController |
Validation of input parameters is omitted for brevity. In the Purchase method, the customer checks to see if there’s enough inventory in the store and, if so, decreases the product amount.
为了简洁起见,输入参数的验证被省略了。在 Purchase 方法中,客户检查商店中是否有足够的库存,如果有,则减少产品数量。
The act of making a purchase is a business use case with both intra-system and inter-system communications. The inter-system communications are those between the CustomerController application service and the two external systems: the thirdparty application (which is also the client initiating the use case) and the email gateway. The intra-system communication is between the Customer and the Store domain classes (figure 5.13).
购买行为是一个具有系统内和系统间通信的业务用例。系统间通信是 CustomerController 应用服务和两个外部系统之间的通信:第三方应用程序(也是启动用例的客户端)和电子邮件网关。系统内的通信是 Customer 和 Store 领域类之间的通信(图 5.13)。
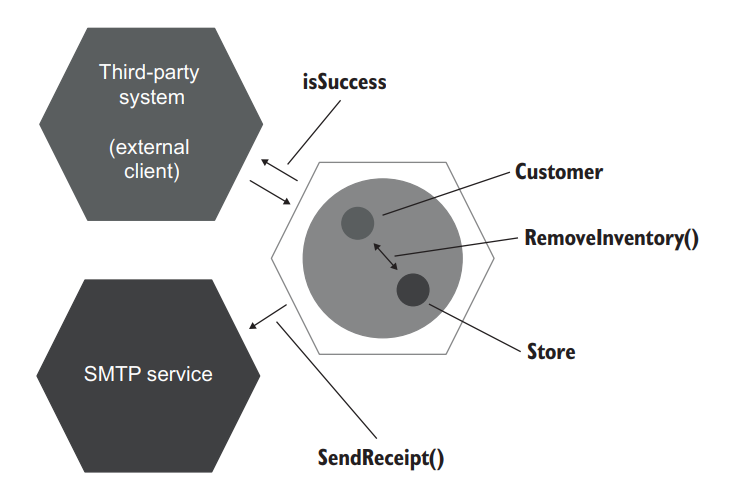
Figure 5.13 The example in listing 5.9 represented using the hexagonal architecture. The communications between the hexagons are inter-system communications. The communication inside the hexagon is intra-system. 图5.13 用六边形结构表示列表 5.9 中的例子。六边形之间的通信是系统间通信。六边形内部的通信是系统内的。
In this example, the call to the SMTP service is a side effect that is visible to the external world and thus forms the observable behavior of the application as a whole.
在这个例子中,对 SMTP 服务的调用是一个对外部世界可见的副作用,因此形成了整个应用程序的可观察行为。
It also has a direct connection to the client’s goals. The client of the application is the third-party system. This system’s goal is to make a purchase, and it expects the customer to receive a confirmation email as part of the successful outcome.
它也与客户的目标有直接的联系。该应用程序的客户是第三方系统。这个系统的目标是进行购买,它希望客户能收到一封确认邮件作为成功结果的一部分。
The call to the SMTP service is a legitimate reason to do mocking. It doesn’t lead to test fragility because you want to make sure this type of communication stays in place even after refactoring. The use of mocks helps you do exactly that.
对 SMTP 服务的调用是一个合法的理由来进行 mocking。它不会导致测试的脆弱性,因为你想确保这种类型的通信即使在重构后也能保持不变。使用 mock 可以帮助你做到这一点。
The next listing shows an example of a legitimate use of mocks.
下一个清单显示了一个合法使用 mock 的例子。
Listing 5.10 Mocking that doesn’t lead to fragile tests 模拟不会导致脆弱的测试
1 | [] |
Note that the isSuccess flag is also observable by the external client and also needs verification. This flag doesn’t need mocking, though; a simple value comparison is enough.
请注意,isSuccess 标志也是可以被外部客户端观察到的,也需要验证。不过这个标志不需要模拟,一个简单的值比较就足够了。
Let’s now look at a test that mocks the communication between Customer and Store.
现在让我们看一下模拟 Customer 和 Store 之间通信的测试。
Listing 5.11 Mocking that leads to fragile tests 模拟会导致脆弱的测试
1 | [] |
Unlike the communication between CustomerController and the SMTP service, the RemoveInventory() method call from Customer to Store doesn’t cross the application boundary: both the caller and the recipient reside inside the application. Also, this method is neither an operation nor a state that helps the client achieve its goals. The client of these two domain classes is CustomerController with the goal of making a purchase. The only two members that have an immediate connection to this goal are customer.Purchase() and store.GetInventory(). The Purchase() method initiates the purchase, and GetInventory() shows the state of the system after the purchase is completed. The RemoveInventory() method call is an intermediate step on the way to the client’s goal—an implementation detail.
与 CustomerController 和 SMTP 服务之间的通信不同,从 Customer 到 Store 的 RemoveInventory() 方法调用并没有跨越应用程序的边界:调用者和接收者都在应用程序内部。另外,这个方法既不是一个操作,也不是一个帮助客户实现其目标的状态。这两个领域类的客户端是 CustomerController,目标是进行购买。与这个目标有直接联系的只有两个成员:customer.Purchase() 和 store.GetInventory()。Purchase() 方法启动了购买,GetInventory() 显示了购买完成后系统的状态。RemoveInventory() 方法的调用是通往客户目标的中间步骤–一个实现细节。
5.4 重新审视经典学派与伦敦学派的单元测试
The classical vs. London schools of unit testing, revisited
As a reminder from chapter 2 (table 2.1), table 5.2 sums up the differences between the classical and London schools of unit testing.
作为第 2 章(表2.1)的提醒,表 5.2 总结了单元测试的经典学派和伦敦学派之间的区别。
Table 5.2 The differences between the London and classical schools of unit testing
| Isolation of | A unit is | Uses test doubles for | |
|---|---|---|---|
| London school | Units | A class | All but immutable dependencies |
| Classical school | Unit tests | A class or a set of classes | Shared dependencies |
In chapter 2, I mentioned that I prefer the classical school of unit testing over the London school. I hope now you can see why. The London school encourages the use of mocks for all but immutable dependencies and doesn’t differentiate between intrasystem and inter-system communications. As a result, tests check communications between classes just as much as they check communications between your application and external systems.
在第二章中,我提到我更喜欢单元测试的经典学派而不是伦敦学派。我希望现在你能明白为什么。伦敦学派鼓励对所有的依赖使用 mocks,但不可变的依赖除外,并且不区分系统内和系统间的通信。结果是,测试检查类之间的通信就像检查应用程序和外部系统之间的通信一样多。
This indiscriminate use of mocks is why following the London school often results in tests that couple to implementation details and thus lack resistance to refactoring. As you may remember from chapter 4, the metric of resistance to refactoring (unlike the other three) is mostly a binary choice: a test either has resistance to refactoring or it doesn’t. Compromising on this metric renders the test nearly worthless.
这种不加区分地使用 mocks 的做法,就是为什么遵循伦敦学派的做法,往往会导致测试与实现细节的耦合,从而对重构缺乏抵抗力。你可能还记得第四章,抵御重构的指标(与其他三个不同)主要是一个二元选择:一个测试要么对重构有抵抗力,要么没有。在这个指标上的妥协使测试几乎毫无价值。
The classical school is much better at this issue because it advocates for substituting only dependencies that are shared between tests, which almost always translates into out-of-process dependencies such as an SMTP service, a message bus, and so on. But the classical school is not ideal in its treatment of inter-system communications, either. This school also encourages excessive use of mocks, albeit not as much as the London school.
经典学派在这个问题上要好得多,因为它主张只替换测试之间共享的依赖,这几乎总是转化为进程外的依赖,如 SMTP 服务、消息总线等等。但是,经典学派在处理系统间通信方面也不理想。这个学派也鼓励过度使用 mock,尽管没有伦敦学派那么多。
5.4.1 并非所有进程外依赖项都应 mock
Not all out-of-process dependencies should be mocked out
Before we discuss out-of-process dependencies and mocking, let me give you a quick refresher on types of dependencies (refer to chapter 2 for more details):
在我们讨论进程外依赖和 mock 之前,让我给你快速复习一下依赖的类型(更多细节请参考第二章):
- Shared dependency—A dependency shared by tests (not production code) 由测试共享的依赖(不是生产代码)
- Out-of-process dependency—A dependency hosted by a process other than the program’s execution process (for example, a database, a message bus, or an SMTP service) 由程序执行进程以外的进程托管的依赖(例如,数据库、消息总线或 SMTP 服务)。
- Private dependency—Any dependency that is not shared 任何不共享的依赖
The classical school recommends avoiding shared dependencies because they provide the means for tests to interfere with each other’s execution context and thus prevent those tests from running in parallel. The ability for tests to run in parallel, sequentially, and in any order is called test isolation.
经典学派建议避免共享依赖,因为它们为测试提供了干扰彼此执行环境的手段,从而阻止这些测试并行运行。测试能够以任何顺序并行运行的能力,被称为测试隔离。
If a shared dependency is not out-of-process, then it’s easy to avoid reusing it in tests by providing a new instance of it on each test run. In cases where the shared dependency is out-of-process, testing becomes more complicated. You can’t instantiate a new database or provision a new message bus before each test execution; that would drastically slow down the test suite. The usual approach is to replace such dependencies with test doubles—mocks and stubs.
如果一个共享的依赖不是进程外的,那么很容易避免在测试中重复使用它,在每个测试运行中提供一个新的实例。在共享依赖是进程外的情况下,测试变得更加复杂。你不能在每次测试执行前实例化一个新的数据库或提供一个新的消息总线;这将大大降低测试套件的速度。通常的方法是用测试替身 mock 和 stub 来替代这种依赖。
Not all out-of-process dependencies should be mocked out, though. If an out-ofprocess dependency is only accessible through your application, then communications with such a dependency are not part of your system’s observable behavior. An out-of-process dependency that can’t be observed externally, in effect, acts as part of your application (figure 5.14).
不过,并不是所有进程外的依赖都应该被 mock。如果一个进程外的依赖只能通过你的应用程序访问,那么与这种依赖的通信就不是你系统可观察行为的一部分。一个不能被外部观察的进程外依赖,实际上是作为你的应用程序的一部分(图 5.14)。
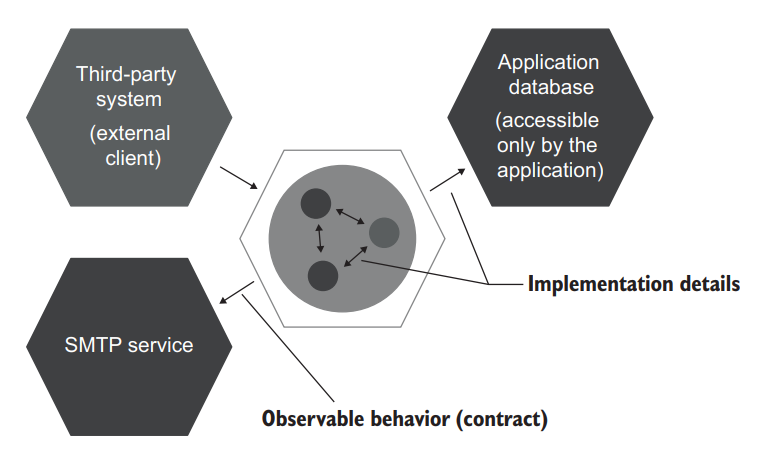
Figure 5.14 Communications with an out-of-process dependency that can’t be observed externally are implementation details. They don’t have to stay in place after refactoring and therefore shouldn’t be verified with mocks. 图 5.14 有进程外依赖的通信,不能从外部观察,是实现细节。它们在重构后不需要保持原状,因此不应该用 mocks 来验证。
Remember, the requirement to always preserve the communication pattern between your application and external systems stems from the necessity to maintain backward compatibility. You have to maintain the way your application talks to external systems. That’s because you can’t change those external systems simultaneously with your application; they may follow a different deployment cycle, or you might simply not have control over them.
请记住,始终保持你的应用程序和外部系统之间的通信模式的要求是源于保持向后兼容性的需要。你必须保持你的应用程序与外部系统交互的方式。这是因为你不可能与你的应用程序同时改变这些外部系统;它们可能遵循不同的部署周期,或者你可能根本无法控制它们。
But when your application acts as a proxy to an external system, and no client can access it directly, the backward-compatibility requirement vanishes. Now you can deploy your application together with this external system, and it won’t affect the clients. The communication pattern with such a system becomes an implementation detail.
但是,当你的应用程序作为外部系统的代理,并且没有客户端可以直接访问它时,向后兼容的要求就消失了。现在你可以把你的应用程序和这个外部系统一起部署,而且不会影响到客户端。与这样一个系统的通信模式成为一个实现细节。
A good example here is an application database: a database that is used only by your application. No external system has access to this database. Therefore, you can modify the communication pattern between your system and the application database in any way you like, as long as it doesn’t break existing functionality. Because that database is completely hidden from the eyes of the clients, you can even replace it with an entirely different storage mechanism, and no one will notice.
一个很好的例子是应用数据库:一个只被你的应用程序使用的数据库。没有外部系统可以访问这个数据库。因此,你可以以任何方式修改你的系统和应用数据库之间的通信模式,只要它不破坏现有的功能。因为这个数据库完全隐藏在客户的视线之外,你甚至可以用一个完全不同的存储机制来替代它,而没有人会注意到。
The use of mocks for out-of-process dependencies that you have a full control over also leads to brittle tests. You don’t want your tests to turn red every time you split a table in the database or modify the type of one of the parameters in a stored procedure. The database and your application must be treated as one system.
对你完全控制的进程外的依赖使用 mocks 也会导致测试变脆弱。你不希望你的测试在每次拆分数据库中的一个表或修改存储过程中的一个参数类型时都变成红色。数据库和你的应用程序必须被视为一个系统。
This obviously poses an issue. How would you test the work with such a dependency without compromising the feedback speed, the third attribute of a good unit test? You’ll see this subject covered in depth in the following two chapters.
这显然带来了一个问题。你如何在不影响反馈速度(一个好的单元测试的第三个属性)的情况下测试有这样一个依赖的工作?在接下来的两章中,你会看到这个主题的深入阐述。
5.4.2 使用 mocks 来验证行为
Using mocks to verify behavior
Mocks are often said to verify behavior. In the vast majority of cases, they don’t. The way each individual class interacts with neighboring classes in order to achieve some goal has nothing to do with observable behavior; it’s an implementation detail.
人们常说 Mocks 可以验证行为。在绝大多数情况下,它们并不是这样。为了实现某些目标,每个单独的类与相邻的类进行交互的方式与可观察的行为无关;这是一个实现细节。
Verifying communications between classes is akin to trying to derive a person’s behavior by measuring the signals that neurons in the brain pass among each other. Such a level of detail is too granular. What matters is the behavior that can be traced back to the client goals. The client doesn’t care what neurons in your brain light up when they ask you to help. The only thing that matters is the help itself—provided by you in a reliable and professional fashion, of course. Mocks have something to do with behavior only when they verify interactions that cross the application boundary and only when the side effects of those interactions are visible to the external world.
验证类之间的通信类似于试图通过测量大脑中的神经元相互间传递的信号来推导出一个人的行为。这样的细节水平过于细化。重要的是可以追溯到客户端目标的行为。客户并不关心当他们要求你帮忙时,你大脑中的哪些神经元会亮起来。唯一重要的是帮忙本身–当然是由你以可靠和专业的方式提供的。只有当 mocks 验证跨越应用边界的交互,并且只有当这些交互的副作用对外部世界可见时,mocks 才与行为有关。
总结
Summary
Test double is an overarching term that describes all kinds of non-productionready, fake dependencies in tests. There are five variations of test doubles— dummy, stub, spy, mock, and fake—that can be grouped in just two types: mocks and stubs. Spies are functionally the same as mocks; dummies and fakes serve the same role as stubs.
测试替身(Test Double)是一个总称,用于描述测试中各种非生产就绪的假依赖。测试替身有五种变体–dummy、stub、spy、mock 和 fake–可归纳为两种类型:mock 和 stubs。spy 在功能上与 mock 相同;dummy 和 fake 与 stub 的作用相同。
Mocks help emulate and examine outcoming interactions: calls from the SUT to its dependencies that change the state of those dependencies. Stubs help emulate incoming interactions: calls the SUT makes to its dependencies to get input data.
Mocks 有助于模拟和检查传出的交互:从 SUT 到其依赖项的调用,这些调用会改变依赖项的状态。存根(stubs)有助于模拟传入的交互:SUT 为获取输入数据而对其依赖对象进行的调用。
A mock (the tool) is a class from a mocking library that you can use to create a mock (the test double) or a stub.
模拟(工具)是模拟库中的一个类,你可以用它来创建一个模拟(测试替身)或存根。
Asserting interactions with stubs leads to fragile tests. Such an interaction doesn’t correspond to the end result; it’s an intermediate step on the way to that result, an implementation detail.
断言与存根的交互会导致脆弱的测试。这种交互与最终结果并不对应;它只是通向最终结果的中间步骤,是一个实现细节。
The command query separation (CQS) principle states that every method should be either a command or a query but not both. Test doubles that substitute commands are mocks. Test doubles that substitute queries are stubs.
命令查询分离(CQS)原则指出,每个方法要么是命令,要么是查询,但不能两者兼而有之。替代命令的测试替身是模拟。替代查询的测试替身是存根。
All production code can be categorized along two dimensions: public API versus private API, and observable behavior versus implementation details. Code publicity is controlled by access modifiers, such as private, public, and internal keywords. Code is part of observable behavior when it meets one of the following requirements (any other code is an implementation detail):
所有生产代码都可以从两个维度进行分类:开放 API 与私有 API,可观察行为与实现细节。代码的公开性由访问修饰符控制,如 private、public 和内部关键字。当代码满足以下要求之一时,它就是可观察行为的一部分(任何其他代码都是实现细节):
It exposes an operation that helps the client achieve one of its goals. An operation is a method that performs a calculation or incurs a side effect.
它暴露了一个操作,帮助客户端实现其目标之一。操作是一种执行计算或产生副作用的方法。
It exposes a state that helps the client achieve one of its goals. State is the current condition of the system.
它暴露了一个状态,可帮助客户端实现其目标之一。状态是系统的当前状态。
Well-designed code is code whose observable behavior coincides with the public API and whose implementation details are hidden behind the private API. A code leaks implementation details when its public API extends beyond the observable behavior.
设计良好的代码是指其可观察行为与开放 API 一致,而其实现细节隐藏在私有 API 之后的代码。如果代码的开放 API 超出了可观察行为的范围,那么代码就会泄露实现细节。
Encapsulation is the act of protecting your code against invariant violations. Exposing implementation details often entails a breach in encapsulation because clients can use implementation details to bypass the code’s invariants.
封装是保护代码不被违反不变量的行为。暴露实现细节往往会破坏封装,因为客户端可以利用实现细节绕过代码的不变量
Hexagonal architecture is a set of interacting applications represented as hexagons. Each hexagon consists of two layers: domain and application services.
六边形架构是一组以六边形表示的交互应用程序。每个六边形由两层组成:领域和应用服务。
Hexagonal architecture emphasizes three important aspects:
六边形架构强调三个重要方面:
Separation of concerns between the domain and application services layers. The domain layer should be responsible for the business logic, while the application services should orchestrate the work between the domain layer and external applications.
领域层和应用服务层之间的关注点分离。领域层应负责业务逻辑,而应用服务应协调领域层与外部应用程序之间的工作。
A one-way flow of dependencies from the application services layer to the domain layer. Classes inside the domain layer should only depend on each other; they should not depend on classes from the application services layer.
从应用服务层到领域层的单向依赖流。领域层内的类只能相互依赖,而不能依赖应用服务层的类。
External applications connect to your application through a common interface maintained by the application services layer. No one has a direct access to the domain layer.
外部应用程序通过由应用程序服务层维护的开放接口连接到您的应用程序。没有人可以直接访问领域层。
Each layer in a hexagon exhibits observable behavior and contains its own set of implementation details.
六边形中的每一层都有可观察到的行为,并包含自己的一套实现细节。
There are two types of communications in an application: intra-system and inter-system. Intra-system communications are communications between classes inside the application. Inter-system communication is when the application talks to external applications.
应用程序中有两种类型的通信:系统内通信和系统间通信。系统内通信是指应用程序内部类之间的通信。系统间通信是指应用程序与外部应用程序之间的通信。
Intra-system communications are implementation details. Inter-system communications are part of observable behavior, with the exception of external systems that are accessible only through your application. Interactions with such systems are implementation details too, because the resulting side effects are not observed externally.
系统内通信是实现细节。系统间通信是可观察行为的一部分,但只能通过应用程序访问的外部系统除外。与此类系统的交互也属于实现细节,因为由此产生的副作用无法从外部观察到。
Using mocks to assert intra-system communications leads to fragile tests. Mocking is legitimate only when it’s used for inter-system communications—communications that cross the application boundary—and only when the side effects of those communications are visible to the external world.
使用模拟来断言系统内部的通信会导致脆弱的测试。只有当模拟用于系统间通信–跨越应用程序边界的通信–并且只有当这些通信的副作用对外部世界可见时,模拟才是合法的。