单元测试原则、实践与模式(四)
译者声明:本译文仅作为学习的记录,不作为任务商业用途,如有侵权请告知我删除。
本文禁止转载!
请支持原书正版:https://www.manning.com/books/unit-testing
第四章 好的单元测试的四大支柱
Chapter 4 The four pillars of a good unit test
This chapter covers 本章内容涵盖
- Exploring dichotomies between aspects of a good unit test 探讨一个好的单元测试的各个方面之间的对立关系
- Defining an ideal test 定义一个理想的测试
- Understanding the Test Pyramid 理解测试金字塔
- Using black-box and white-box testing 使用黑盒和白盒测试
Now we are getting to the heart of the matter. In chapter 1, you saw the properties of a good unit test suite:
现在我们进入了问题的核心。在第1章中,你看到了一个好的单元测试套件的特性:
- It is integrated into the development cycle. You only get value from tests that you actively use; there’s no point in writing them otherwise. 它被整合到开发周期中。只有在你积极使用测试时,你才会从中获得价值;否则写它们就没有意义。
- It targets only the most important parts of your code base. Not all production code deserves equal attention. It’s important to differentiate the heart of the application (its domain model) from everything else. This topic is tackled in chapter 7. 它只针对你的代码库中最重要的部分。不是所有的生产代码都值得同样的关注。将应用程序的核心部分(它的领域模型)与其他东西区分开来是很重要的。这个问题将在第7章解决。
- It provides maximum value with minimum maintenance costs. To achieve this last attribute, you need to be able to 它以最小的维护成本提供最大的价值。为了实现这最后一个属性,你需要能够
- Recognize a valuable test (and, by extension, a test of low value) 识别有价值的测试(以及延伸到低价值的测试)
- Write a valuable test 编写一个有价值的测试
As we discussed in chapter 1, recognizing a valuable test and writing a valuable test are two separate skills. The latter skill requires the former one, though; so, in this chapter, I’ll show how to recognize a valuable test. You’ll see a universal frame of reference with which you can analyze any test in the suite. We’ll then use this frame of reference to go over some popular unit testing concepts: the Test Pyramid and black-box versus white-box testing.
正如我们在第一章所讨论的,识别一个有价值的测试和编写一个有价值的测试是两种不同的技能。不过,后一种技能需要前一种技能;因此,在本章中,我将展示如何识别有价值的测试。你会看到一个通用的参考框架,你可以用它来分析套件中的任何测试。然后,我们将使用这个参考框架来讨论一些流行的单元测试概念:测试金字塔和黑盒与白盒测试。
Buckle up: we are starting out
准备好:我们开始了
4.1 深入好的单元测试的四大支柱
Diving into the four pillars of a good unit test
A good unit test has the following four attributes: 一个好的单元测试有以下四个属性:
- Protection against regressions 防止回归
- Resistance to refactoring 抵御重构
- Fast feedback 快速反馈
- Maintainability 可维护性
译者注
regression:回归、衰退,回归测试的主要目的是验证系统在进行更改后仍能按照预期工作,包括确保现有功能的正确性不受影响。
These four attributes are foundational. You can use them to analyze any automated test, be it unit, integration, or end-to-end. Every such test exhibits some degree of each attribute. In this section, I define the first two attributes; and in section 4.2, I describe the intrinsic connection between them.
这四个属性是基础性的。你可以用它们来分析任何自动化测试,无论是单元、集成还是端到端。每一个这样的测试都在一定程度上表现出每个属性。在本节中,我定义了前两个属性;在4.2节中,我描述了它们之间的内在联系。
4.1.1 第一支柱 防止回归
The first pillar: Protection against regressions
Let’s start with the first attribute of a good unit test: protection against regressions. As you know from chapter 1, a regression is a software bug. It’s when a feature stops working as intended after some code modification, usually after you roll out new functionality.
让我们从好的单元测试的第一个属性开始:防止回归。正如你在第一章所知道的,回归是一个软件错误。它是指一个功能在某些代码修改后停止工作,通常是在你推出新功能之后。
Such regressions are annoying (to say the least), but that’s not the worst part about them. The worst part is that the more features you develop, the more chances there are that you’ll break one of those features with a new release. An unfortunate fact of programming life is that code is not an asset, it’s a liability. The larger the code base, the more exposure it has to potential bugs. That’s why it’s crucial to develop a good protection against regressions. Without such protection, you won’t be able to sustain the project growth in a long run—you’ll be buried under an ever-increasing number of bugs.
这样的回归是令人讨厌的(至少可以这么说),但这不是最糟糕的部分。最糟糕的是,你开发的功能越多,你在新版本中破坏其中一个功能的机率就越大。编程生活中一个不幸的事实是,代码不是一种资产,而是一种责任。代码库越大,就越有可能出现错误。这就是为什么制定一个良好的保护措施来防止回归是至关重要的。没有这样的保护,你将无法维持项目的长期增长–你将被埋没在越来越多的 bug 之下。
To evaluate how well a test scores on the metric of protecting against regressions, you need to take into account the following:
要评估一个测试在防止回归方面的指标如何,你需要考虑到以下几点:
- The amount of code that is executed during the test 测试过程中执行的代码量
- The complexity of that code 该代码的复杂性
- The code’s domain significance 代码的领域意义
Generally, the larger the amount of code that gets executed, the higher the chance that the test will reveal a regression. Of course, assuming that this test has a relevant set of assertions, you don’t want to merely execute the code. While it helps to know that this code runs without throwing exceptions, you also need to validate the outcome it produces.
一般来说,被执行的代码量越大,测试发现回归的机率就越高。当然,前提是这个测试具有相关的断言集,你并不想仅仅执行代码。虽然知道这段代码运行时没有抛出异常是有帮助的,但你也需要验证它产生的结果。
Note that it’s not only the amount of code that matters, but also its complexity and domain significance. Code that represents complex business logic is more important than boilerplate code—bugs in business-critical functionality are the most damaging.
请注意,重要的不仅是代码的数量,还有它的复杂性和领域意义。代表复杂业务逻辑的代码比模板代码更重要–关键业务功能中的错误是最具破坏性的。
On the other hand, it’s rarely worthwhile to test trivial code. Such code is short and doesn’t contain a substantial amount of business logic. Tests that cover trivial code don’t have much of a chance of finding a regression error, because there’s not a lot of room for a mistake. An example of trivial code is a single-line property like this:
另一方面,对无足轻重的代码进行测试是不值得的。这些代码很短,而且不包含大量的业务逻辑。涵盖无足轻重代码的测试没有太多的机会发现回归错误,因为没有太多的空间来犯错。一个微不足道的代码的例子是像这样的单行属性:
1 | public class User |
Furthermore, in addition to your code, the code you didn’t write also counts: for example, libraries, frameworks, and any external systems used in the project. That
code influences the working of your software almost as much as your own code. For the best protection, the test must include those libraries, frameworks, and external systems in the testing scope, in order to check that the assumptions your software makes about these dependencies are correct.
此外,除了你的代码外,你没有写的代码也算在内:例如,库、框架和项目中使用的任何外部系统。这些代码对你的软件工作的影响几乎和你自己的代码一样大。为了获得最好的保护,测试必须将这些库、框架和外部系统纳入测试范围,以检查你的软件对这些依赖关系的假设是否正确。
TIP
To maximize the metric of protection against regressions, the test needs to aim at exercising as much code as possible.
为了最大限度地防止回归,测试需要以执行尽可能多的代码为目标。
4.1.2 第二支柱:抵御重构
The second pillar: Resistance to refactoring
The second attribute of a good unit test is resistance to refactoring—the degree to which a test can sustain a refactoring of the underlying application code without turning red (failing).
好的单元测试的第二个属性是抵御重构–测试在多大程度上可以承受底层应用代码的重构而不变红(失败)。
译者注
变红(失败):指的是在 IDE 中运行测试时,失败的测试会以红色标识,通过的测试以绿色标识。
DEFINITION
Refactoring means changing existing code without modifying its observable behavior. The intention is usually to improve the code’s nonfunctional characteristics: increase readability and reduce complexity. Some examples of refactoring are renaming a method and extracting a piece of code into a new class.
重构意味着在不修改其可观察行为的情况下改变现有的代码。其目的通常是为了改善代码的非功能特性:增加可读性和降低复杂性。重构的一些例子是重命名一个方法和将一段代码提取到一个新的类中。
Picture this situation. You developed a new feature, and everything works great. The feature itself is doing its job, and all the tests are passing. Now you decide to clean up the code. You do some refactoring here, a little bit of modification there, and everything looks even better than before. Except one thing—the tests are failing. You look more closely to see exactly what you broke with the refactoring, but it turns out that you didn’t break anything. The feature works perfectly, just as before. The problem is that the tests are written in such a way that they turn red with any modification of the underlying code. And they do that regardless of whether you actually break the functionality itself.
想象一下这种情况。你开发了一个新的功能,而且一切运行良好。该功能本身正在做它的工作,而且所有的测试都通过了。现在你决定整理一下代码。你在这里做了一些重构,在那里做了一些修改,一切看起来都比以前好。除了一件事:测试失败了。你仔细观察了一下,看看你的重构到底破坏了什么,但事实证明,你没有破坏任何东西。该功能工作得很好,就像以前一样。问题是,测试是以这样的方式编写的,即在对底层代码进行任何修改时都会变成红色。而且不管你是否真的破坏了功能本身,它们都会失败。
This situation is called a false positive. A false positive is a false alarm. It’s a result indicating that the test fails, although in reality, the functionality it covers works as intended. Such false positives usually take place when you refactor the code—when you modify the implementation but keep the observable behavior intact. Hence the name for this attribute of a good unit test: resistance to refactoring.
这种情况被称为假阳性。假阳性是一个错误的警报。这是一个表明测试失败的结果,尽管在现实中,它所涵盖的功能如期工作。这种假阳性通常发生在你重构代码的时候–当你修改实现但保持可观察行为不变的时候。因此,一个好的单元测试的这个属性被称为:抵御重构。
To evaluate how well a test scores on the metric of resisting to refactoring, you need to look at how many false positives the test generates. The fewer, the better.
要评估一个测试在抵御重构的指标上有多好,你需要看一下测试产生了多少假阳性。越少越好。
Why so much attention on false positives? Because they can have a devastating effect on your entire test suite. As you may recall from chapter 1, the goal of unit testing is to enable sustainable project growth. The mechanism by which the tests enable sustainable growth is that they allow you to add new features and conduct regular refactorings without introducing regressions. There are two specific benefits here:
为什么如此关注假阳性现象?因为它们会对你的整个测试套件产生破坏性的影响。你可能还记得第一章,单元测试的目标是使项目持续增长。测试实现可持续增长的机制是,它们允许你在不引入回归的情况下增加新功能和进行定期重构。这里有两个具体的好处:
- Tests provide an early warning when you break existing functionality. Thanks to such early warnings, you can fix an issue long before the faulty code is deployed to production, where dealing with it would require a significantly larger amount of effort. 当你破坏现有的功能时,测试提供了一个早期警告。由于这种早期警告,你可以在有问题的代码被部署到生产中之前很长时间内修复这个问题,因为在生产中处理这个问题需要很大的努力。
- You become confident that your code changes won’t lead to regressions. Without such confidence, you will be much more hesitant to refactor and much more likely to leave the code base to deteriorate. 你变得有信心,你的代码修改不会导致回归。如果没有这样的信心,你就会更加犹豫不决地进行重构,并且更有可能让代码库恶化。
False positives interfere with both of these benefits:
假阳性干扰了这两个好处:
If tests fail with no good reason, they dilute your ability and willingness to react to problems in code. Over time, you get accustomed to such failures and stop paying as much attention. After a while, you start ignoring legitimate failures, too, allowing them to slip into production.
如果测试在没有充分理由的情况下失败,它们会削弱你对代码中的问题做出反应的能力和意愿。随着时间的推移,你会习惯于这样的失败,而不再那么关注了。一段时间后,你也开始忽视合法的失败,让它们溜进生产。
On the other hand, when false positives are frequent, you slowly lose trust in the test suite. You no longer perceive it as a reliable safety net—the perception is diminished by false alarms. This lack of trust leads to fewer refactorings, because you try to reduce code changes to a minimum in order to avoid regressions.
另一方面,当假阳性反应频繁时,你会慢慢失去对测试套件的信任。你不再认为它是一个可靠的安全网–错误的警报削弱了这种感觉。这种信任的缺乏导致了更少的重构,因为你试图将代码的变化减少到最小,以避免回归。
A story from the trenches 一个来自一线的故事
I once worked on a project with a rich history. The project wasn’t too old, maybe two or three years; but during that period of time, management significantly shifted the direction they wanted to go with the project, and development changed direction accordingly. During this change, a problem emerged: the code base accumulated large chunks of leftover code that no one dared to delete or refactor. The company no longer needed the features that code provided, but some parts of it were used in new functionality, so it was impossible to get rid of the old code completely.
我曾经在一个有着丰富历史的项目上工作。这个项目不算太老,可能有两三年了;但在那段时间里,管理层大大改变了他们想要的项目方向,开发也相应地改变了方向。在这个变化中,出现了一个问题:代码库中积累了大块的遗留代码,没有人敢于删除或重构。公司不再需要这些代码提供的功能,但其中的一些部分被用于新的功能中,所以不可能完全摆脱旧的代码。
The project had good test coverage. But every time someone tried to refactor the old features and separate the bits that were still in use from everything else, the tests failed. And not just the old tests—they had been disabled long ago—but the new tests, too. Some of the failures were legitimate, but most were not—they were false positives.
该项目有良好的测试覆盖率。但是每当有人试图重构旧的功能,并将仍在使用的部分与其他部分分开时,测试就会失败。不仅仅是旧的测试–它们早就被禁用了–新的测试也是如此。有些失败是合法的,但大多数是不合法的,它们是假阳性。
At first, the developers tried to deal with the test failures. However, since the vast majority of them were false alarms, the situation got to the point where the developers ignored such failures and disabled the failing tests. The prevailing attitude was, “If it’s because of that old chunk of code, just disable the test; we’ll look at it later.”
起初,开发人员试图处理测试失败的问题。然而,由于绝大多数都是假阳性,情况发展到了这样的地步:开发人员无视这些故障,并禁用失败的测试。普遍的态度是:”如果是因为那块旧的代码,就禁用测试;我们以后再看”。
Everything worked fine for a while—until a major bug slipped into production. One of the tests correctly identified the bug, but no one listened; the test was disabled along with all the others. After that accident, the developers stopped touching the old code entirely.
一切都运行良好一段时间,直到一个重大错误不慎进入生产环境。其中一个测试正确地识别了这个错误,但没有人听取;该测试与其他所有测试一起被禁用了。事故发生后,开发人员完全停止了对旧代码的修改。
This story is typical of most projects with brittle tests. First, developers take test failures at face value and deal with them accordingly. After a while, people get tired of tests crying “wolf” all the time and start to ignore them more and more. Eventually, there comes a moment when a bunch of real bugs are released to production because developers ignored the failures along with all the false positives.
这个故事是大多数典型的有脆弱测试的项目。首先,开发人员把测试失败看成是表面现象,并相应地处理它们。一段时间后,人们厌倦了测试一直在喊 “狼来了”,开始越来越多地忽视它们。最终,有一个时刻,一堆真正的 bug 被发布到生产中,因为开发人员忽略了这些失败和所有的假阳性结果。
You don’t want to react to such a situation by ceasing all refactorings, though. The correct response is to re-evaluate the test suite and start reducing its brittleness. I cover this topic in chapter 7.
不过,你不希望通过停止所有的重构来应对这种情况。正确的做法是重新评估测试套件,并开始降低其脆弱性。我在第 7 章中谈到了这个主题。
4.1.3 什么原因导致假阳性?
What causes false positives?
So, what causes false positives? And how can you avoid them?
那么,什么原因导致假阳性?你怎样才能避免它们呢?
The number of false positives a test produces is directly related to the way the test is structured. The more the test is coupled to the implementation details of the system under test (SUT), the more false alarms it generates. The only way to reduce the chance of getting a false positive is to decouple the test from those implementation details. You need to make sure the test verifies the end result the SUT delivers: its observable behavior, not the steps it takes to do that. Tests should approach SUT verification from the end user’s point of view and check only the outcome meaningful to that end user. Everything else must be disregarded (more on this topic in chapter 5).
一个测试产生的假阳性的数量与测试的结构方式直接相关。测试与被测系统(SUT)的实现细节耦合得越多,它产生的假阳性就越多。减少假阳性的机率的唯一方法是使测试与这些实现细节脱钩。你需要确保测试验证 SUT 提供的最终结果:它的可观察行为,而不是它为实现这一目标所采取的步骤。测试应该从终端用户的角度来验证 SUT,并且只检查对终端用户有意义的结果。其他的一切都必须被忽略(更多关于这个话题在第五章)。
The best way to structure a test is to make it tell a story about the problem domain. Should such a test fail, that failure would mean there’s a disconnect between the story and the actual application behavior. It’s the only type of test failure that benefits you— such failures are always on point and help you quickly understand what went wrong. All other failures are just noise that steer your attention away from things that matter.
构建测试的最好方法是让它讲述一个关于问题领域的故事。如果这样的测试失败了,那就意味着故事和实际的应用行为之间存在着脱节。这是唯一有利于你的测试失败类型–这种失败总是很关键,帮助你快速了解出错的原因。所有其他的失败都是噪音,把你的注意力从重要的事情上引开。
Take a look at the following example. In it, the MessageRenderer class generates an HTML representation of a message containing a header, a body, and a footer.
看一下下面的例子。在这个例子中,MessageRenderer 类生成了一个包含页眉、正文和页脚的信息的 HTML 表示。
Listing 4.1 Generating an HTML representation of a message 生成 HTML 格式的消息
1 | public class Message |
The MessageRenderer class contains several sub-renderers to which it delegates the actual work on parts of the message. It then combines the result into an HTML document. The sub-renderers orchestrate the raw text with HTML tags. For example:
MessageRenderer 类包含几个子渲染器,它将 Message 的部分实际工作委托给它们。然后,它将结果合并为一个 HTML 文档。这些子渲染器将原始文本与 HTML 标签协调起来。比如说:
1 | public class BodyRenderer : IRenderer |
How can MessageRenderer be tested? One possible approach is to analyze the algorithm this class follows.
如何测试 MessageRenderer?一个可能的方法是分析这个类所遵循的算法。
Listing 4.2 Verifying that MessageRenderer has the correct structure 验证 MessageRenderer 具有正确的结构
1 | [] |
This test checks to see if the sub-renderers are all of the expected types and appear in the correct order, which presumes that the way MessageRenderer processes messages must also be correct. The test might look good at first, but does it really verify MessageRenderer’s observable behavior? What if you rearrange the sub-renderers, or replace one of them with a new one? Will that lead to a bug?
这个测试检查子渲染器是否都是预期的类型,并且以正确的顺序出现,这就假定 MessageRenderer 处理消息的方式也必须是正确的。这个测试一开始可能看起来不错,但它真的验证了 MessageRenderer 的可观察行为吗?如果你重新排列子渲染器,或者用一个新的子渲染器替换其中一个子渲染器呢?那会导致一个 bug 吗?
Not necessarily. You could change a sub-renderer’s composition in such a way that the resulting HTML document remains the same. For example, you could replace BodyRenderer with a BoldRenderer, which does the same job as BodyRenderer. Or you could get rid of all the sub-renderers and implement the rendering directly in MessageRenderer.
不一定。你可以改变一个子渲染器的组成方式,使产生的 HTML 文档保持不变。例如,你可以用一个 BoldRenderer 替换 BodyRenderer,它的工作与 BodyRenderer 相同。或者你可以摆脱所有的子渲染器,直接在MessageRenderer 中实现渲染。
Still, the test will turn red if you do any of that, even though the end result won’t change. That’s because the test couples to the SUT’s implementation details and not the outcome the SUT produces. This test inspects the algorithm and expects to see one particular implementation, without any consideration for equally applicable alternative implementations (see figure 4.1).
尽管如此,如果你做了这些,测试还是会变红,尽管最终的结果不会改变。这是因为测试与 SUT 的实现细节相联系,而不是 SUT 产生的结果。这个测试检查了算法,希望看到一个特定的实现,而没有考虑同样适用的替代实现(见图 4.1)。
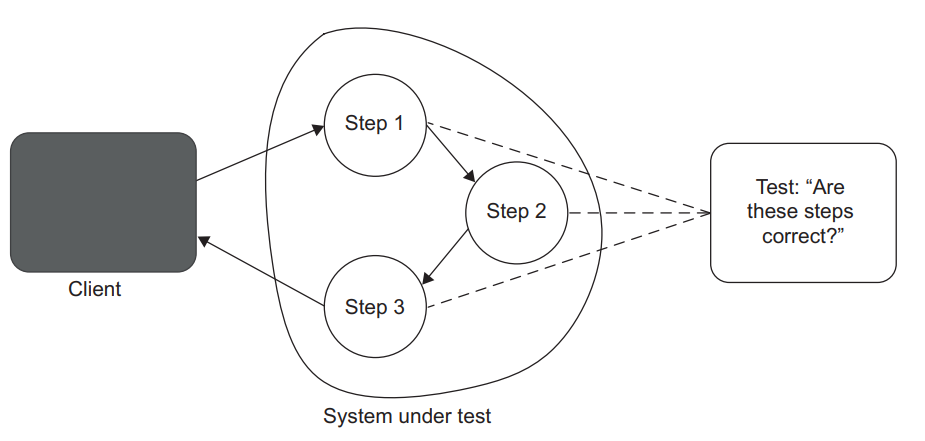
Figure 4.1 A test that couples to the SUT’s algorithm. Such a test expects to see one particular implementation (the specific steps the SUT must take to deliver the result) and therefore is brittle. Any refactoring of the SUT’s implementation would lead to a test failure.
图4.1 一个与 SUT 的算法相关联的测试。这样的测试期望看到一个特定的实现(SUT 必须采取的具体步骤,以提供结果),因此是脆弱的。任何对 SUT 实现的重构都会导致测试失败。
Any substantial refactoring of the MessageRenderer class would lead to a test failure. Mind you, the process of refactoring is changing the implementation without affecting the application’s observable behavior. And it’s precisely because the test is concerned with the implementation details that it turns red every time you change those details.
任何对 MessageRenderer 类的实质性重构都会导致测试失败。请注意,重构的过程是在不影响应用程序的可观察行为的情况下改变实现。而正是因为测试关注的是实现细节,所以每次改变这些细节都会变红。
Therefore, tests that couple to the SUT’s implementation details are not resistant to refactoring. Such tests exhibit all the shortcomings I described previously:
因此,与 SUT 的实现细节相联系的测试是不能抵御重构的。这样的测试表现出我之前描述的所有缺点:
- They don’t provide an early warning in the event of regressions—you simply ignore those warnings due to little relevance. 它们不能在回归时提供早期警告–由于相关性不强,你只是忽略了这些警告。
- They hinder your ability and willingness to refactor. It’s no wonder—who would like to refactor, knowing that the tests can’t tell which way is up when it comes to finding bugs? 它们阻碍了你重构的能力和意愿。这也难怪–谁会愿意重构,因为他知道测试在发现 bug 的时候无法判断哪种方式是正确的?
The next listing shows the most egregious example of brittleness in tests that I’ve ever encountered, in which the test reads the source code of the MessageRenderer class and compares it to the “correct” implementation.
下一个清单显示了我所遇到的测试中最令人无语的例子,其中测试读取了 MessageRenderer 类的源代码,并将其与 “正确 “的实现进行比较。
Listing 4.3 Verifying the source code of the MessageRenderer class 验证 MessageRenderer 类的源代码
1 | [] |
Of course, this test is just plain ridiculous; it will fail should you modify even the slightest detail in the MessageRenderer class. At the same time, it’s not that different from the test I brought up earlier. Both insist on a particular implementation without taking into consideration the SUT’s observable behavior. And both will turn red each time you change that implementation. Admittedly, though, the test in listing 4.3 will break more often than the one in listing 4.2.
当然,这个测试是非常荒谬的;如果你在 MessageRenderer 类中修改了哪怕最微小的细节,它都会失败。同时,它与我前面提到的测试没有什么不同。两者都坚持一个特定的实现,而没有考虑到 SUT 的可观察行为。而且每次你改变这个实现时,两者都会变成红色。诚然,列表 4.3 中的测试会比列表 4.2 中的测试更容易失败。
4.1.4 以最终结果为目标,而不是实现细节
Aim at the end result instead of implementation details
As I mentioned earlier, the only way to avoid brittleness in tests and increase their resistance to refactoring is to decouple them from the SUT’s implementation details—keep as much distance as possible between the test and the code’s inner workings, and instead aim at verifying the end result. Let’s do that: let’s refactor the test from listing 4.2 into something much less brittle.
正如我前面提到的,避免测试变脆弱并增加其抵御重构的能力的唯一方法是使其与 SUT 的实现细节脱钩–在测试和代码的内部工作之间保持尽可能多的距离,而以验证最终结果为目标。让我们这样做:让我们重构列表 4.2 中的测试,使其变得不那么脆弱。
To start off, you need to ask yourself the following question: What is the final outcome you get from MessageRenderer? Well, it’s the HTML representation of a message. And it’s the only thing that makes sense to check, since it’s the only observable result you get out of the class. As long as this HTML representation stays the same, there’s no need to worry about exactly how it’s generated. Such implementation details are irrelevant. The following code is the new version of the test.
首先,你需要问自己以下问题: 你从 MessageRenderer 得到的最终结果是什么?嗯,它是一条 HTML 格式的消息。这也是唯一值得检查的东西,因为它是你从这个类中得到的唯一可观察的结果。只要这个 HTML 格式保持不变,就没有必要关注它到底是如何生成的。这样的实现细节是不相关的。下面的代码是新版本的测试。
Listing 4.4 Verifying the outcome that MessageRenderer produces 验证 MessageRenderer 产生的结果
1 | [] |
This test treats MessageRenderer as a black box and is only interested in its observable behavior. As a result, the test is much more resistant to refactoring—it doesn’t care what changes you make to the SUT as long as the HTML output remains the same (figure 4.2). Notice the profound improvement in this test over the original version. It aligns itself with the business needs by verifying the only outcome meaningful to end users—how a message is displayed in the browser. Failures of such a test are always on point: they communicate a change in the application behavior that can affect the customer and thus should be brought to the developer’s attention. This test will produce few, if any, false positives.
这个测试把 MessageRenderer 当作一个黑盒,只对它的可观察行为感兴趣。因此,该测试抵御重构的能力更强–只要 HTML 输出保持不变,它就不会在乎你对 SUT 做了什么改变(图4.2)。注意到这个测试比原来的版本有很大的改进。它通过验证对终端用户有意义的唯一结果–信息在浏览器中的显示,使自己与业务需求保持一致。这种测试的失败总是有意义的:它们传达了应用行为的变化,会影响到客户,因此应该引起开发者的注意。这种测试将产生很少的假阳性结果,如果有的话。
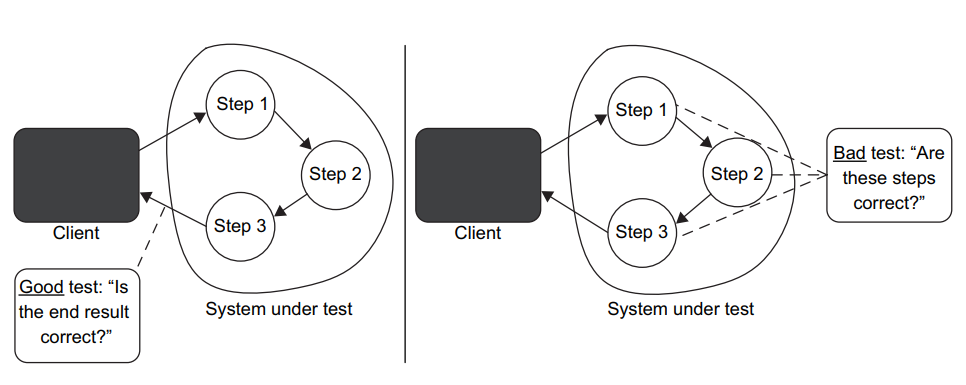
Figure 4.2 The test on the left couples to the SUT’s observable behavior as opposed to implementation details. Such a test is resistant to refactoring—it will trigger few, if any, false positives. 图4.2 左边的测试与SUT 的可观察行为相关联,而不是实现细节。这样的测试是能抵御重构的–它几乎不会触发假阳性(如果有的话)。
Why few and not none at all? Because there could still be changes in MessageRenderer that would break the test. For example, you could introduce a new parameter in the Render() method, causing a compilation error. And technically, such an error counts as a false positive, too. After all, the test isn’t failing because of a change in the application’s behavior.
为什么是几乎不会,而不是完全没有?因为 MessageRenderer 中仍有可能发生变化,从而破坏测试。例如,你可以在 Render() 方法中引入一个新的参数,导致一个编译错误。从技术上讲,这样的错误也算作一个假阳性。毕竟,测试失败并不是因为应用程序行为的改变。
But this kind of false positive is easy to fix. Just follow the compiler and add a new parameter to all tests that invoke the Render() method. The worse false positives are those that don’t lead to compilation errors. Such false positives are the hardest to deal with—they seem as though they point to a legitimate bug and require much more time to investigate.
但是这种假阳性是很容易解决的。只要跟随编译器,在所有调用 Render() 方法的测试中添加一个新参数。更糟糕的假阳性是那些不会导致编译错误的假阳性。这种假阳性是最难处理的–它们看起来好像是指向一个合法的错误,需要更多的时间来调查。
4.2 前两个属性之间的内在联系
The intrinsic connection between the first two attributes
As I mentioned earlier, there’s an intrinsic connection between the first two pillars of a good unit test—protection against regressions and resistance to refactoring. They both contribute to the accuracy of the test suite, though from opposite perspectives. These two attributes also tend to influence the project differently over time: while it’s important to have good protection against regressions very soon after the project’s initiation, the need for resistance to refactoring is not immediate.
正如我前面提到的,一个好的单元测试的前两个支柱之间有内在的联系–防止回归和抵御重构。尽管从相反的角度来看,它们都有助于提高测试套件的准确性。随着时间的流逝,这两个属性也往往会对项目产生不同的影响:虽然在项目启动后不久就防止回归很重要,但对抵御重构需求并不是立即的。
In this section, I talk about
在这一节中,我谈到了
- Maximizing test accuracy 最大限度地提高测试的准确性
- The importance of false positives and false negatives 假阳性和假阴性的重要性
4.2.1 最大化测试准确性
Maximizing test accuracy
Let’s step back for a second and look at the broader picture with regard to test results. When it comes to code correctness and test results, there are four possible outcomes, as shown in figure 4.3. The test can either pass or fail (the rows of the table). And the functionality itself can be either correct or broken (the table’s columns).
让我们退一步,看看关于测试结果的更普遍的情况。当涉及到代码正确性和测试结果时,有四种可能的结果,如图4.3 所示。测试要么通过,要么失败(表格中的行)。而功能本身既可以是正确的,也可以是错误的(表中的列)。
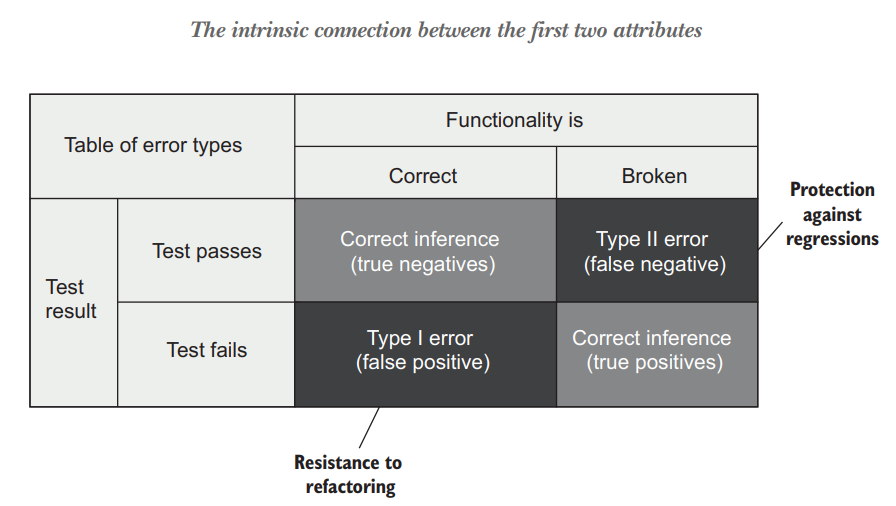
Figure 4.3 The relationship between protection against regressions and resistance to refactoring. Protection against regressions guards against false negatives (type II errors). Resistance to refactoring minimizes the number of false positives (type I errors). 图4.3 防止回归和抵御重构之间的关系。防止回归可以防止错误的否定(type II 类型的错误)。 抵御重构使假阳性(I型错误)的数量最小化。
The situation when the test passes and the underlying functionality works as intended is a correct inference: the test correctly inferred the state of the system (there are no bugs in it). Another term for this combination of working functionality and a passing test is true negative.
测试通过并且底层功能按预期工作的情况是一个正确的推断:测试正确地推断了系统的状态(其中没有错误)。工作功能和通过测试的这种组合的另一个术语是真阴性。
Similarly, when the functionality is broken and the test fails, it’s also a correct inference. That’s because you expect to see the test fail when the functionality is not working properly. That’s the whole point of unit testing. The corresponding term for this situation is true positive.
同样,当功能被破坏而测试失败时,这也是一个正确的推断。这是因为当功能不能正常工作时,你希望看到测试失败。这就是单元测试的全部意义所在。这种情况的对应术语是真阳性。
But when the test doesn’t catch an error, that’s a problem. This is the upper-right quadrant, a false negative. And this is what the first attribute of a good test—protection against regressions—helps you avoid. Tests with a good protection against regressions help you to minimize the number of false negatives—type II errors.
但是当测试没有捕捉到错误时,这就是一个问题。这是右上角的象限,是假阴性。而这正是一个好的测试的第一个属性–防止回归–帮助你避免的。有良好防止回归的测试可以帮助你尽量减少假阴性的 type II 类型的错误的数量。
On the other hand, there’s a symmetric situation when the functionality is correct but the test still shows a failure. This is a false positive, a false alarm. And this is what the second attribute—resistance to refactoring—helps you with.
另一方面,有一种对立的情况,即功能是正确的,但测试仍然显示失败。这是一个假阳性,一个假警报。这就是第二个属性–抵御重构–帮助你解决的问题。
All these terms (false positive, type I error and so on) have roots in statistics, but can also be applied to analyzing a test suite. The best way to wrap your head around them is to think of a flu test. A flu test is positive when the person taking the test has the flu. The term positive is a bit confusing because there’s nothing positive about having the flu. But the test doesn’t evaluate the situation as a whole. In the context of testing, positive means that some set of conditions is now true. Those are the conditions the creators of the test have set it to react to. In this particular example, it’s the presence of the flu. Conversely, the lack of flu renders the flu test negative.
所有这些术语(假阳性,type I 类型错误等等)都源于统计学,但也可以应用于分析测试套件。解释这些术语的最好方法是类比流感测试。当接受测试的人患有流感时,流感测试是阳性的。阳性这个词有点令人困惑,因为患流感并没有什么阳性。但是测试并不评估整个情况。在测试的背景下,阳性意味着某些条件现在是真的。这些条件是测试的创造者所设定的反应。在这个特定的例子中,它是流感的存在。反过来说,没有流感就意味着流感测试是阴性的。
Now, when you evaluate how accurate the flu test is, you bring up terms such as false positive or false negative. The probability of false positives and false negatives tells you how good the flu test is: the lower that probability, the more accurate the test.
现在,当你评估流感测试的准确性时,你就会提到假阳性或假阴性这样的术语。假阳性和假阴性的概率告诉你流感测试有多好:这个概率越低,测试就越准确。
This accuracy is what the first two pillars of a good unit test are all about. Protection against regressions and resistance to refactoring aim at maximizing the accuracy of the test suite. The accuracy metric itself consists of two components:
这种准确性是一个好的单元测试的前两个支柱的全部内容。防止回归和抵御重构旨在使测试套件的准确性最大化。准确性指标本身由两部分组成:
- How good the test is at indicating the presence of bugs (lack of false negatives, the sphere of protection against regressions) 测试在指示 bug 的存在方面有多好(没有假阴性,防止回归的范围)。
- How good the test is at indicating the absence of bugs (lack of false positives, the sphere of resistance to refactoring) 测试在指示没有 bug 方面有多好(没有假阳性,抵域重构的范围)。
Another way to think of false positives and false negatives is in terms of signal-to-noise ratio. As you can see from the formula in figure 4.4, there are two ways to improve test accuracy. The first is to increase the numerator, signal: that is, make the test better at finding regressions. The second is to reduce the denominator, noise: make the test better at not raising false alarms.
另一种思考假阳性和假阴性的方式是用信噪比来计算。从图4.4 的公式中可以看出,有两种方法可以提高测试的准确性。第一种是增加分子,即信号:也就是说,使测试更好地找到回归的情况。第二种是减少分母,即噪音:使测试更好地不引起错误警报。
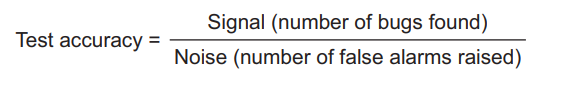
Figure 4.4 A test is accurate insofar as it generates a strong signal (is capable of finding bugs) with as little noise (false alarms) as possible. 图4.4 一个测试是准确的,因为它能产生一个强大的信号(能够发现 bug),并尽可能地减少噪音(假阳性)。
Both are critically important. There’s no use for a test that isn’t capable of finding any bugs, even if it doesn’t raise false alarms. Similarly, the test’s accuracy goes to zero when it generates a lot of noise, even if it’s capable of finding all the bugs in code. These findings are simply lost in the sea of irrelevant information.
这两点都是非常重要的。一个没有能力发现任何 bug 的测试是没有用的,即使它没有引起错误的警报。同样,当测试产生大量的噪音时,即使它能够发现代码中的所有 bug,其准确性也会降至零。这些发现只是在不相关信息的海洋中丢失了。
4.2.2 假阳性和假阴性的重要性: 动态
The importance of false positives and false negatives: The dynamics
In the short term, false positives are not as bad as false negatives. In the beginning of a project, receiving a wrong warning is not that big a deal as opposed to not being warned at all and running the risk of a bug slipping into production. But as the project grows, false positives start to have an increasingly large effect on the test suite (figure 4.5).
在短期内,假阳性并不像假阴性那样糟糕。在项目的开始阶段,相对于根本没有被警报,并且有错误滑入生产的风险,收到错误的警报并不是什么大问题。但随着项目的发展,假阳性开始对测试套件产生越来越大的影响(图4.5)。
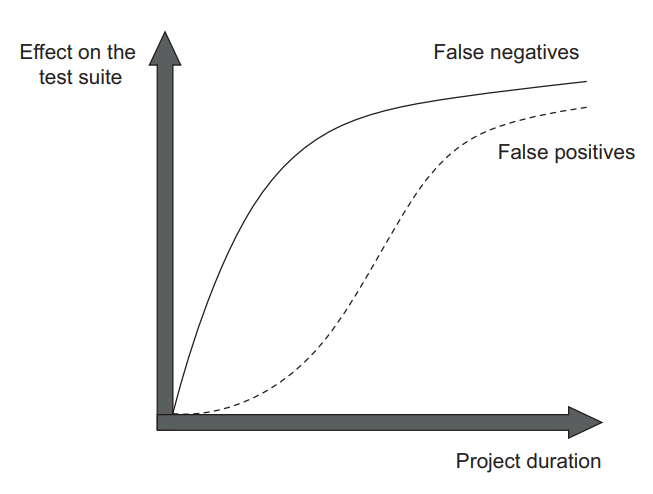
Figure 4.5 False positives (false alarms) don’t have as much of a negative effect in the beginning. But they become increasingly important as the project grows—as important as false negatives (unnoticed bugs). 图4.5 假阳性(错误警报)在开始时没有那么大的负面影响。但随着项目的发展,它们变得越来越重要–与假阴性(未被注意的错误)一样重要。
Why are false positives not as important initially? Because the importance of refactoring is also not immediate; it increases gradually over time. You don’t need to conduct many code clean-ups in the beginning of the project. Newly written code is often shiny and flawless. It’s also still fresh in your memory, so you can easily refactor it even if tests raise false alarms.
为什么假阳性在最初没有那么重要?因为重构的重要性也不是立竿见影的;它随着时间的推移逐渐增加。在项目的开始阶段,你不需要进行很多代码整理。新写的代码往往是光鲜无暇的。它在你的记忆中也是新鲜的,即使测试引起错误的警报,你也可以很容易地重构它。
But as time goes on, the code base deteriorates. It becomes increasingly complex and disorganized. Thus you have to start conducting regular refactorings in order to mitigate this tendency. Otherwise, the cost of introducing new features eventually becomes prohibitive.
但是,随着时间的推移,代码库会恶化。它变得越来越复杂和无序。因此,你必须开始定期进行重构,以减轻这种趋势。否则,引入新功能的成本最终会变得难以承受。
As the need for refactoring increases, the importance of resistance to refactoring in tests increases with it. As I explained earlier, you can’t refactor when the tests keep crying “wolf” and you keep getting warnings about bugs that don’t exist. You quickly lose trust in such tests and stop viewing them as a reliable source of feedback.
随着重构需求的增加,测试中抵御重构的重要性也随之增加。正如我前面所解释的,当测试一直在喊 “狼来了”,你不断收到关于不存在的错误的警报时,你就无法进行重构。你很快就会失去对这些测试的信任,不再把它们看作是可靠的反馈来源。
Despite the importance of protecting your code against false positives, especially in the later project stages, few developers perceive false positives this way. Most people tend to focus solely on improving the first attribute of a good unit test—protection against regressions, which is not enough to build a valuable, highly accurate test suite that helps sustain project growth.
尽管保护你的代码免受假阳性的影响很重要,尤其是在项目的后期阶段,但很少有开发者这样看待假阳性。大多数人倾向于只关注改进一个好的单元测试的第一个属性–防止回归,这不足以建立一个有价值的、高度准确的测试套件,帮助维持项目的发展。
The reason, of course, is that far fewer projects get to those later stages, mostly because they are small and the development finishes before the project becomes too big. Thus developers face the problem of unnoticed bugs more often than false alarms that swarm the project and hinder all refactoring undertakings. And so, people optimize accordingly. Nevertheless, if you work on a medium to large project, you have to pay equal attention to both false negatives (unnoticed bugs) and false positives (false alarms).
当然,原因是进入这些后期阶段的项目要少得多,主要是因为这些项目规模小,在项目变得太大之前就完成了开发。因此,开发人员面临的问题是,未被注意到的 bug 比错误的警报更多,这些错误蜂拥而至,阻碍了所有的重构事业。于是,人们就进行了相应的优化。然而,如果你在一个大中型项目上工作,你必须对假阴性(未注意到的bug)和假阳性(假警报)给予同等关注。
4.3 第三和第四支柱:快速反馈和可维护性
The third and fourth pillars: Fast feedback and maintainability
In this section, I talk about the two remaining pillars of a good unit test:
在这一节中,我谈一谈一个好的单元测试的其余两个支柱:
- Fast feedback 快速反馈
- Maintainability 可维护性
As you may remember from chapter 2, fast feedback is an essential property of a unit test. The faster the tests, the more of them you can have in the suite and the more often you can run them.
你可能还记得第二章,快速反馈是单元测试的一个基本属性。测试越快,套件中的测试就越多,可以运行的次数也越多。
With tests that run quickly, you can drastically shorten the feedback loop, to the point where the tests begin to warn you about bugs as soon as you break the code, thus reducing the cost of fixing those bugs almost to zero. On the other hand, slow tests delay the feedback and potentially prolong the period during which the bugs remain unnoticed, thus increasing the cost of fixing them. That’s because slow tests discourage you from running them often, and therefore lead to wasting more time moving in a wrong direction.
有了快速运行的测试,你可以大大缩短反馈回路,以至于一旦你破坏了代码,测试就开始警告你的 bug,从而将修复这些 bug 的成本几乎降为零。另一方面,慢速测试会延迟反馈,并有可能延长 bug 不被注意的时间,从而增加修复它们的成本。这是因为缓慢的测试使你不愿意经常运行它们,因此导致浪费更多的时间在一个错误的方向上前进。
Finally, the fourth pillar of good units tests, the maintainability metric, evaluates maintenance costs. This metric consists of two major components:
最后,好的单元测试的第四个支柱,可维护性指标,评估了维护成本。这个指标包括两个主要部分:
- How hard it is to understand the test—This component is related to the size of the test. The fewer lines of code in the test, the more readable the test is. It’s also easier to change a small test when needed. Of course, that’s assuming you don’t try to compress the test code artificially just to reduce the line count. The quality of the test code matters as much as the production code. Don’t cut corners when writing tests; treat the test code as a first-class citizen.
- 测试有多难理解–这个部分与测试的规模有关。测试中的代码行数越少,测试的可读性就越强。在需要的时候,改变一个小的测试也比较容易。当然,这是假设你不试图为了减少行数而人为地压缩测试代码。测试代码的质量和生产代码一样重要。编写测试时不要偷工减料;要把测试代码当作一等的公民。
- How hard it is to run the test—If the test works with out-of-process dependencies, you have to spend time keeping those dependencies operational: reboot the database server, resolve network connectivity issues, and so on.
- 运行测试有多难–如果测试与进程外的依赖关系一起工作,你必须花时间保持这些依赖关系的运行:重新启动数据库服务器,解决网络连接问题,等等。
4.4 寻找一个理想的测试
In search of an ideal test
Here are the four attributes of a good unit test once again:
下面再次介绍一个好的单元测试的四个属性:
- Protection against regressions 防止回归
- Resistance to refactoring 抵御重构
- Fast feedback 快速反馈
- Maintainability 可维护性
These four attributes, when multiplied together, determine the value of a test. And by multiplied, I mean in a mathematical sense; that is, if a test gets zero in one of the attributes, its value turns to zero as well:
当这四个属性相乘时,就决定了测试的价值。我说的乘法,是指数学意义上的;也就是说,如果一个测试在其中一个属性中得到零,那么它的价值也变为零:
1 | Value estimate = [0..1] * [0..1] * [0..1] * [0..1] |
TIP
In order to be valuable, the test needs to score at least something in all four categories.
为了有价值,测试需要在所有四个类别中都至少得到一些分数。
Of course, it’s impossible to measure these attributes precisely. There’s no code analysis tool you can plug a test into and get the exact numbers. But you can still evaluate the test pretty accurately to see where a test stands with regard to the four attributes. This evaluation, in turn, gives you the test’s value estimate, which you can use to decide whether to keep the test in the suite.
当然,要精确地度量这些属性是不可能的。没有代码分析工具可以让您插入测试并获得准确的数字。但是您仍然可以相当准确地评估测试,以查看测试在这四个属性方面的位置。这个评估,反过来,为您提供了测试的价值估计,您可以使用它来决定是否将测试保留在套件中。
Remember, all code, including test code, is a liability. Set a fairly high threshold for the minimum required value, and only allow tests in the suite if they meet this threshold. A small number of highly valuable tests will do a much better job sustaining project growth than a large number of mediocre tests.
记住,所有的代码,包括测试代码,都是一种责任。为最低要求的价值设定一个相当高的门槛,只有当测试满足这个门槛时,才允许它们进入套件。少量高价值的测试将比大量平庸的测试更能维持项目的增长。
I’ll show some examples shortly. For now, let’s examine whether it’s possible to create an ideal test.
我将很快展示一些例子。现在,让我们研究一下是否有可能创建一个理想的测试。
4.4.1 是否有可能创建一个理想的测试?
Is it possible to create an ideal test?
An ideal test is a test that scores the maximum in all four attributes. If you take the minimum and maximum values as 0 and 1 for each of the attributes, an ideal test must get 1 in all of them.
一个理想的测试是一个在所有四个属性中都得到最大分数的测试。如果你把每个属性的最小值和最大值看作是 0 和 1,那么一个理想的测试必须在所有的属性中得到 1。
Unfortunately, it’s impossible to create such an ideal test. The reason is that the first three attributes—protection against regressions, resistance to refactoring, and fast feedback— are mutually exclusive. It’s impossible to maximize them all: you have to sacrifice one of the three in order to max out the remaining two.
不幸的是,要创建这样一个理想的测试是不可能的。原因是前三个属性–防止回归,抵御重构,以及快速反馈–是相互排斥的。不可能将它们全部最大化:你必须牺牲三者中的一个,才能将其余两个最大化。
Moreover, because of the multiplication principle (see the calculation of the value estimate in the previous section), it’s even trickier to keep the balance. You can’t just forgo one of the attributes in order to focus on the others. As I mentioned previously, a test that scores zero in one of the four categories is worthless. Therefore, you have to maximize these attributes in such a way that none of them is diminished too much. Let’s look at some examples of tests that aim at maximizing two out of three attributes at the expense of the third and, as a result, have a value that’s close to zero.
此外,由于乘法原则(见上一节中价值评估的计算),保持平衡就更加困难了。你不能为了专注于其他属性而放弃其中一个属性。正如我之前提到的,一个在四个类别中的一个得分为零的测试是没有价值的。因此,你必须将这些属性最大化,使它们中的任何一个都不会被削弱太多。让我们看看一些测试的例子,这些测试旨在最大限度地提高三个属性中的两个属性,而牺牲第三个属性,因此,其数值接近于零。
4.4.2 极端案例#1: 端到端测试
Extreme case #1: End-to-end tests
The first example is end-to-end tests. As you may remember from chapter 2, end-to-end tests look at the system from the end user’s perspective. They normally go through all of the system’s components, including the UI, database, and external applications.
第一个例子是端到端测试。你可能还记得第 2 章,端到端测试是从终端用户的角度看系统的。他们通常会检查系统的所有组件,包括用户界面、数据库和外部应用程序。
Since end-to-end tests exercise a lot of code, they provide the best protection against regressions. In fact, of all types of tests, end-to-end tests exercise the most code—both your code and the code you didn’t write but use in the project, such as external libraries, frameworks, and third-party applications.
由于端到端测试执行了大量的代码,它们提供了针对回归的最佳的保护。事实上,在所有类型的测试中,端到端测试执行了最多的代码–包括你的代码和你没有写但在项目中使用的代码,如外部库、框架和第三方应用程序。
End-to-end tests are also immune to false positives and thus have a good resistance to refactoring. A refactoring, if done correctly, doesn’t change the system’s observable behavior and therefore doesn’t affect the end-to-end tests. That’s another advantage of such tests: they don’t impose any particular implementation. The only thing end-toend tests look at is how a feature behaves from the end user’s point of view. They are as removed from implementation details as tests could possibly be.
端到端测试也不受假阳性的影响,因此能很好的抵御重构。重构,如果做得正确,不会改变系统的可观察行为,因此不会影响端到端测试。这是这种测试的另一个优点:它们不强加任何特定的实现。端到端测试唯一关注的是,从终端用户的角度看,一个功能是如何表现的。它们与实现的细节相去甚远,这也是测试需要做到的。
However, despite these benefits, end-to-end tests have a major drawback: they are slow. Any system that relies solely on such tests would have a hard time getting rapid feedback. And that is a deal-breaker for many development teams. This is why it’s pretty much impossible to cover your code base with only end-to-end tests.
然而,尽管有这些好处,端到端测试有一个主要的缺点:他们很慢。任何仅仅依靠这种测试的系统都很难得到快速反馈。而这对于许多开发团队来说是一个致命的问题。这就是为什么只用端到端测试来覆盖你的代码库几乎是不可能的。
Figure 4.6 shows where end-to-end tests stand with regard to the first three unit testing metrics. Such tests provide great protection against both regression errors and false positives, but lack speed.
图4.6 显示了端到端测试在前三个单元测试指标中的地位。这种测试对回归错误和假阳性都有很好的保护作用,但缺乏速度。
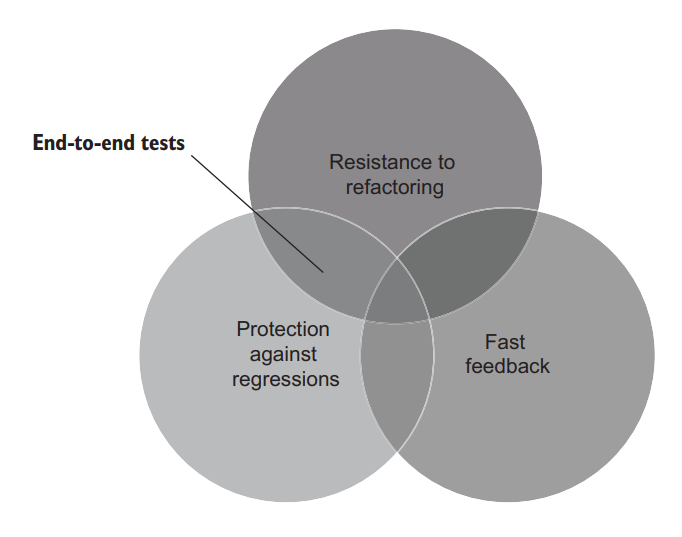
Figure 4.6 End-to-end tests provide great protection against both regression errors and false positives, but they fail at the metric of fast feedback. 图4.6 端到端测试对回归错误和假阳性都有很好的保护作用,但它们在快速反馈的指标上失败了。
4.4.3 极端情况 #2:无足轻重的测试
Extreme case #2: Trivial tests
Another example of maximizing two out of three attributes at the expense of the third is a trivial test. Such tests cover a simple piece of code, something that is unlikely to break because it’s too trivial, as shown in the following listing.
另一个以牺牲第三个属性为代价最大化三个属性中的两个的例子是无足轻重的测试。这样的测试涵盖了一段简单的代码,一些不太可能被破坏的东西,因为它太微不足道了,如下面的列表所示。
Listing 4.5 Trivial test covering a simple piece of code 覆盖一段简单代码的琐碎测试
1 | public class User |
Unlike end-to-end tests, trivial tests do provide fast feedback—they run very quickly. They also have a fairly low chance of producing a false positive, so they have good resistance to refactoring. Trivial tests are unlikely to reveal any regressions, though, because there’s not much room for a mistake in the underlying code.
与端到端测试不同,无足轻重的测试确实提供了快速的反馈–它们运行得非常快。它们产生假阳性的机会也相当低,所以它们很好的抵御重构。不过,无足轻重的测试不太可能发现任何回归错误,因为底层代码中没有太多的错误空间。
Trivial tests taken to an extreme result in tautology tests. They don’t test anything because they are set up in such a way that they always pass or contain semantically meaningless assertions.
无足轻重的测试发展到极端,就变成了同义词测试。它们没有测试任何东西,因为它们被设置成总是通过或包含无语义的断言的方式。
Figure 4.7 shows where trivial tests stand. They have good resistance to refactoring and provide fast feedback, but they don’t protect you from regressions. 图4.7显示了微不足道的测试的情况。它们对重构有很好的抵抗力,并提供快速的反馈,但它们不能保护你免受回归的影响。
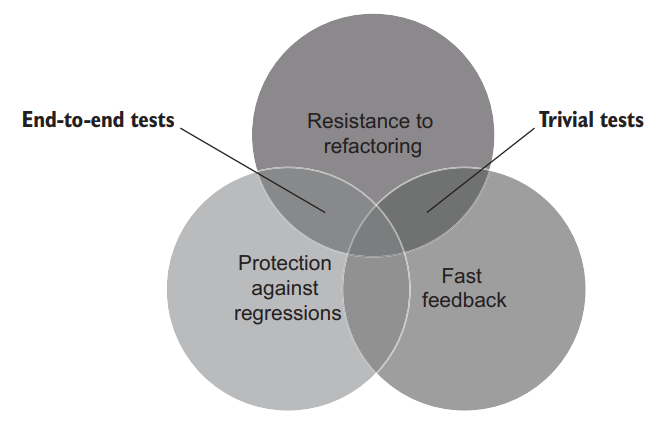
Figure 4.7 Trivial tests have good resistance to refactoring, and they provide fast feedback, but such tests don’t protect you from regressions. 图4.7 无足轻重的测试能很好的抵御重构,它们提供了快速的反馈,但这样的测试并不能保护你免受回归的影响。
4.4.4 极端情况#3: 脆弱测试
Extreme case #3: Brittle tests
Similarly, it’s pretty easy to write a test that runs fast and has a good chance of catching a regression but does so with a lot of false positives. Such a test is called a brittle test: it can’t withstand a refactoring and will turn red regardless of whether the underlying functionality is broken.
同样,写一个运行速度快、有很大机会捕捉到回归的测试是很容易的,但这样做有很多假阳性。这样的测试被称为脆弱测试:它经不起重构,无论底层功能是否被破坏都会变成红色。
You already saw an example of a brittle test in listing 4.2. Here’s another one.
你已经在列表4.2 中看到了一个脆性测试的例子。下面是另一个例子。
Listing 4.6 Test verifying which SQL statement is executed 验证哪个 SQL 语句被执行
1 | public class UserRepository |
This test makes sure the UserRepository class generates a correct SQL statement when fetching a user from the database. Can this test catch a bug? It can. For example, a developer can mess up the SQL code generation and mistakenly use ID instead of UserID, and the test will point that out by raising a failure. But does this test have good resistance to refactoring? Absolutely not. Here are different variations of the SQL statement that lead to the same result:
这个测试确保 UserRepository 类在从数据库中获取用户时生成一个正确的 SQL 语句。这个测试能捕捉一个 bug吗?它可以。例如,开发者可以弄乱 SQL 代码的生成,错误地使用 ID 而不是 UserID,这个测试会通过引起一个失败来指出这一点。但是这个测试能很好的抵御重构吗?绝对不是。下面是导致相同结果的SQL语句的不同变化:
1 | SELECT * FROM dbo.[User] WHERE UserID = 5 |
The test in listing 4.6 will turn red if you change the SQL script to any of these variations, even though the functionality itself will remain operational. This is once again an example of coupling the test to the SUT’s internal implementation details. The test is focusing on hows instead of whats and thus ingrains the SUT’s implementation details, preventing any further refactoring.
如果你把 SQL 脚本改成这些变化中的任何一种,列表4.6 中的测试就会变成红色,尽管功能本身仍然可以运行。这又是一个将测试与 SUT 的内部实现细节耦合的例子。该测试的重点是 “how” 而不是 “what”,因此根植于 SUT 的实现细节,阻止任何进一步的重构。
Figure 4.8 shows that brittle tests fall into the third bucket. Such tests run fast and provide good protection against regressions but have little resistance to refactoring. 图4.8显示,脆弱测试属于第三类。这样的测试运行速度快,很好的防止回归,但几乎无法抵御构。
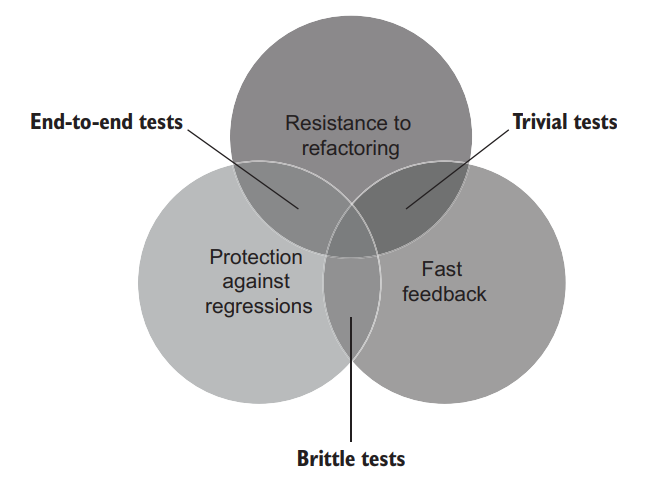
Figure 4.8 Brittle tests run fast and they provide good protection against regressions, but they have little resistance to refactoring. 图 4.8 脆弱测试运行速度很快,它们提供了良好的回归保护,但它们几乎无法抵御重构。
4.4.5 寻找一个理想的测试:结果
In search of an ideal test: The results
The first three attributes of a good unit test (protection against regressions, resistance to refactoring, and fast feedback) are mutually exclusive. While it’s quite easy to come up with a test that maximizes two out of these three attributes, you can only do that at the expense of the third. Still, such a test would have a close-to-zero value due to the multiplication rule. Unfortunately, it’s impossible to create an ideal test that has a perfect score in all three attributes (figure 4.9).
良好的单元测试的前三个属性(防止回归、抵御重构和快速反馈)是互斥的。虽然很容易提出一个最大化这三个属性中两个的测试,但您只能以牺牲第三个属性为代价来做到这一点。尽管如此,由于乘法规则,这样的测试将具有接近零的值。不幸的是,不可能创建一个在所有三个属性中都得分的理想测试(图4.9)。
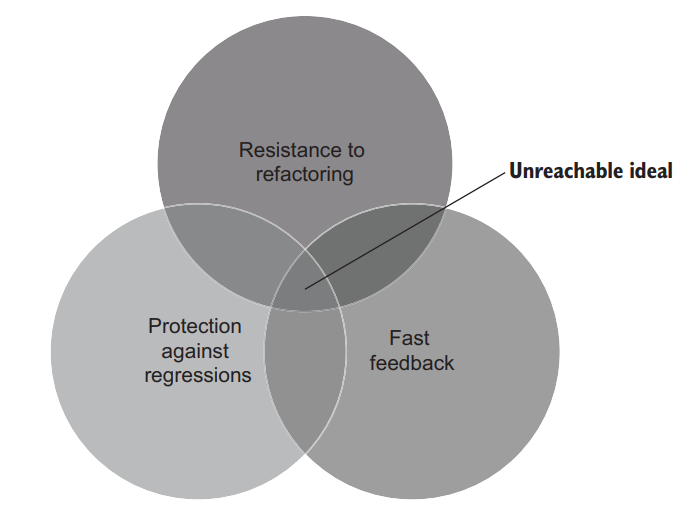
Figure 4.9 It’s impossible to create an ideal test that would have a perfect score in all three attributes. 图4.9 不可能创建一个在所有三个属性上都得满分的理想测试。
The fourth attribute, maintainability, is not correlated to the first three, with the exception of end-to-end tests. End-to-end tests are normally larger in size because of the necessity to set up all the dependencies such tests reach out to. They also require additional effort to keep those dependencies operational. Hence end-to-end tests tend to be more expensive in terms of maintenance costs.
第四个属性(可维护性)与前三个属性无关,但端到端测试除外。端到端测试的规模通常较大,因为必须设置此类测试所涉及的所有依赖项。它们还需要额外的工作来保持这些依赖项的运行。因此,端到端测试在维护成本方面往往更昂贵。
It’s hard to keep a balance between the attributes of a good test. A test can’t have the maximum score in each of the first three categories, and you also have to keep an eye on the maintainability aspect so the test remains reasonably short and simple. Therefore, you have to make trade-offs. Moreover, you should make those trade-offs in such a way that no particular attribute turns to zero. The sacrifices have to be partial and strategic.
要在一个好的测试的属性之间保持平衡是很难的。一个测试不可能在前三类中的每一类都得到最高分,而且你还必须关注可维护性方面,以便测试保持合理的短小和简单。因此,你必须做出权衡。此外,你应该以这样的方式进行权衡,即没有特定的属性变成零。这些牺牲必须是局部的和战略性的。
What should those sacrifices look like? Because of the mutual exclusiveness of protection against regressions, resistance to refactoring, and fast feedback, you may think that the best strategy is to concede a little bit of each: just enough to make room for all three attributes.
这些牺牲应该是什么样子的?由于防止回归、抵御重构和快速反馈的相互排斥,你可能认为最好的策略是在每个属性中让出一点:刚好为所有三个属性留出空间。
In reality, though, resistance to refactoring is non-negotiable. You should aim at gaining as much of it as you can, provided that your tests remain reasonably quick and you don’t resort to the exclusive use of end-to-end tests. The trade-off, then, comes down to the choice between how good your tests are at pointing out bugs and how fast they do that: that is, between protection against regressions and fast feedback. You can view this choice as a slider that can be freely moved between protection against regressions and fast feedback. The more you gain in one attribute, the more you lose on the other (see figure 4.10).
但实际上,抵御重构是不可协商的。只要你的测试能保持相当快的速度,并且不完全使用端到端测试,你就应该尽可能多地使用重构。那么,权衡的结果就是在测试指出错误的能力和速度之间做出选择:也就是说,在防止回归和快速反馈之间做出选择。你可以把这种选择看作是一个滑块,可以在防止回归和快速反馈之间自由移动。在一个属性上获得的收益越多,在另一个属性上损失的就越多(见图 4.10)。
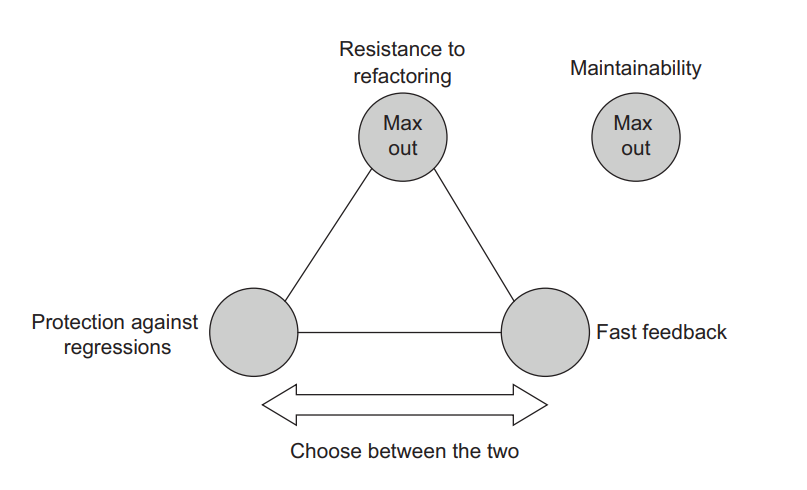
Figure 4.10 The best tests exhibit maximum maintainability and resistance to refactoring; always try to max out these two attributes. The trade-off comes down to the choice between protection against regressions and fast feedback. 图4.10 最好的测试表现出最大的可维护性和抵御重构力;总是试图将这两个属性最大化。权衡的结果是在防止回归和快速反馈之间进行选择。
The reason resistance to refactoring is non-negotiable is that whether a test possesses this attribute is mostly a binary choice: the test either has resistance to refactoring or it doesn’t. There are almost no intermediate stages in between. Thus you can’t concede just a little resistance to refactoring: you’ll have to lose it all. On the other hand, the metrics of protection against regressions and fast feedback are more malleable. You will see in the next section what kind of trade-offs are possible when you choose one over the other.
抵御重构是不可协商的,因为一个测试是否拥有这个属性主要是一个二元选择:测试要么能抵御重构,要么没有。这中间几乎没有中间阶段。因此,你不能只让步一点抵御重构的能力:你将不得不完全失去它。另一方面,防止回归和快速反馈的衡量标准更具可塑性。你将在下一节看到,当你选择其中一个时,可能会有什么样的权衡。
TIP
Eradicating brittleness (false positives) in tests is the first priority on the path to a robust test suite.
消除测试中的脆弱性(假阳性)是实现健壮测试套件的首要任务。
The CAP theorem
CAP定理
The trade-off between the first three attributes of a good unit test is similar to the CAP theorem. The CAP theorem states that it is impossible for a distributed data store to simultaneously provide more than two of the following three guarantees:
一个好的单元测试的前三个属性之间的权衡与 CAP 定理相似。CAP 定理指出,分布式数据存储不可能同时提供以下三种保证中的两种以上:
- Consistency, which means every read receives the most recent write or an error.
- 一致性,这意味着每次读取都会收到最近的写入或错误。
- Availability, which means every request receives a response (apart from outages that affect all nodes in the system).
- 可用性,这意味着每个请求都能得到响应(除了影响系统中所有节点的故障)。
- Partition tolerance, which means the system continues to operate despite network partitioning (losing connection between network nodes).
- 分区容忍性,这意味着尽管网络分区(网络节点之间失去连接),系统仍能继续运行。
The similarity is two-fold:
其相似之处有两点:
- First, there is the two-out-of-three trade-off. 首先,有三分之二的权衡。
- Second, the partition tolerance component in large-scale distributed systems is also non-negotiable. A large application such as, for example, the Amazon website can’t operate on a single machine. The option of preferring consistency and availability at the expense of partition tolerance simply isn’t on the table—Amazon has too much data to store on a single server, however big that server is. 第二,大规模分布式系统中的分区容忍性部分也是不可协商的。一个大型的应用程序,例如,亚马逊网站,不可能在一台机器上运行。以牺牲分区容忍性为代价来选择一致性和可用性是不可能的–Amazon 有太多的数据无法存储在单个服务器上,无论该服务器有多大。
The choice, then, also boils down to a trade-off between consistency and availability. In some parts of the system, it’s preferable to concede a little consistency to gain more availability. For example, when displaying a product catalog, it’s generally fine if some parts of the catalog are out of date. Availability is of higher priority in this scenario. On the other hand, when updating a product description, consistency is more important than availability: network nodes must have a consensus on what the most recent version of that description is, in order to avoid merge conflicts.
那么,这个选择也可以归结为一致性和可用性之间的权衡。在系统的某些部分,为了获得更多的可用性,最好是让步一点一致性。例如,在显示产品目录时,如果目录的某些部分已经过期,一般来说是可以的。在这种情况下,可用性是更优先的。另一方面,在更新产品描述时,一致性比可用性更重要:网络节点必须对该描述的最新版本达成共识,以避免合并冲突。
4.5 探索著名的测试自动化概念
Exploring well-known test automation concepts
The four attributes of a good unit test shown earlier are foundational. All existing, well-known test automation concepts can be traced back to these four attributes. In this section, we’ll look at two such concepts: the Test Pyramid and white-box versus black-box testing.
前面显示的良好的单元测试的四个属性是基础性的。所有现有的、著名的测试自动化概念都可以追溯到这四个属性。在这一节中,我们将看一下这样的两个概念:测试金字塔和白盒与黑盒测试。
4.5.1 拆解测试金字塔
Breaking down the Test Pyramid
The Test Pyramid is a concept that advocates for a certain ratio of different types of tests in the test suite (figure 4.11):
测试金字塔是一个概念,主张测试套件中不同类型的测试要有一定的比例(图4.11):
- Unit tests 单元测试
- Integration tests 集成测试
- End-to-end tests 端到端测试
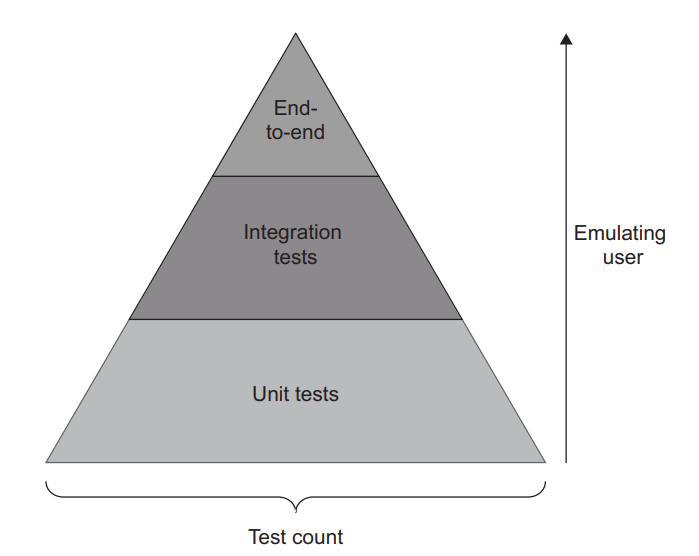
Figure 4.11 The Test Pyramid advocates for a certain ratio of unit, integration, and end-to-end tests. 图4.11 测试金字塔主张单元、集成和端到端测试的一定比例。
The Test Pyramid is often represented visually as a pyramid with those three types of tests in it. The width of the pyramid layers refers to the prevalence of a particular type of test in the suite. The wider the layer, the greater the test count. The height of the layer is a measure of how close these tests are to emulating the end user’s behavior. End-to-end tests are at the top—they are the closest to imitating the user experience. Different types of tests in the pyramid make different choices in the trade-off between fast feedback and protection against regressions. Tests in higher pyramid layers favor protection against regressions, while lower layers emphasize execution speed (figure 4.12).
测试金字塔通常以金字塔的形式表示,里面有这三种类型的测试。金字塔层的宽度是指套件中特定类型的测试的普遍性。层越宽,测试数量就越多。层的高度是衡量这些测试与模拟最终用户行为的接近程度。端到端测试位于顶部–它们最接近于模仿用户体验。金字塔中不同类型的测试在快速反馈和防止回归之间做出不同的选择。金字塔中较高层次的测试偏重于防止回归,而较低层次的测试强调执行速度(图4.12)。
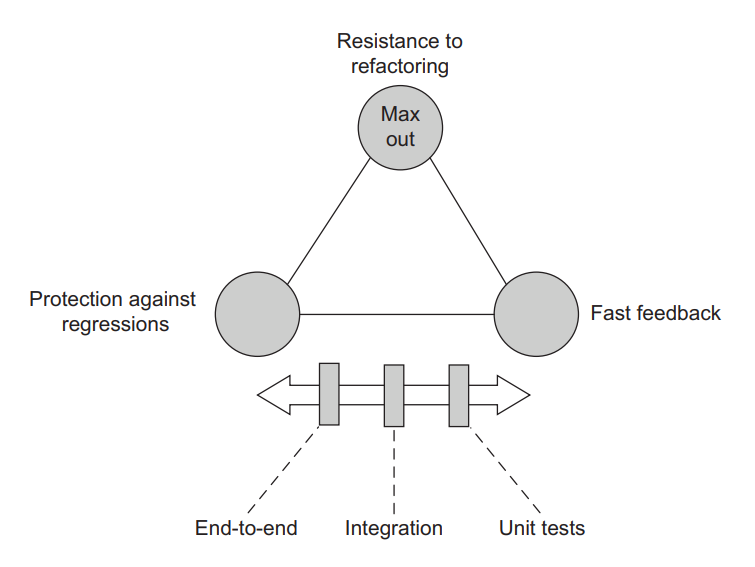
Figure 4.12 Different types of tests in the pyramid make different choices between fast feedback and protection against regressions. End-to-end tests favor protection against regressions, unit tests emphasize fast feedback, and integration tests lie in the middle. 图4.12 金字塔中不同类型的测试在快速反馈和防止回归之间做出了不同的选择。端到端测试偏向于防止回归,单元测试强调快速反馈,而集成测试则处于中间位置。
Notice that neither layer gives up resistance to refactoring. Naturally, end-to-end and integration tests score higher on this metric than unit tests, but only as a side effect of being more detached from the production code. Still, even unit tests should not concede resistance to refactoring. All tests should aim at producing as few false positives as possible, even when working directly with the production code. (How to do that is the topic of the next chapter.)
注意,这两层都没有放弃抵御重构。当然,端到端测试和集成测试在这个指标上比单元测试得分高,但这只是从生产代码中分离出来的一个副作用。尽管如此,即使是单元测试也不应该放弃抵御重构。所有的测试都应该以产生尽可能少的假阳性为目标,即使是在直接与生产代码一起工作时。(如何做到这一点是下一章的主题)。
The exact mix between types of tests will be different for each team and project. But in general, it should retain the pyramid shape: end-to-end tests should be the minority; unit tests, the majority; and integration tests somewhere in the middle.
测试类型之间的确切组合对于每个团队和项目都是不同的。但总的来说,应该保持金字塔的形状:端到端测试应该是少数;单元测试是多数;集成测试在中间某个位置。
The reason end-to-end tests are the minority is, again, the multiplication rule described in section 4.4. End-to-end tests score extremely low on the metric of fast feedback. They also lack maintainability: they tend to be larger in size and require additional effort to maintain the involved out-of-process dependencies. Thus, end-to-end tests only make sense when applied to the most critical functionality—features in which you don’t ever want to see any bugs—and only when you can’t get the same degree of protection with unit or integration tests. The use of end-to-end tests for anything else shouldn’t pass your minimum required value threshold. Unit tests are usually more balanced, and hence you normally have many more of them.
端到端测试是少数的原因是,同样是4.4 节中描述的乘法规则。端到端测试在快速反馈这一指标上得分极低。他们也缺乏可维护性:他们往往规模较大,需要额外的努力来维护所涉及的进程外的依赖关系。因此,端到端测试只有在应用于最关键的功能时才有意义–在这些功能中,你永远不希望看到任何 bug,而且只有在你不能用单元或集成测试获得相同程度的保护时才有意义。在其他方面使用端到端测试不应该超过你的最低要求值门槛。单元测试通常更加平衡,因此你通常有更多的单元测试。
There are exceptions to the Test Pyramid. For example, if all your application does is basic create, read, update, and delete (CRUD) operations with very few business rules or any other complexity, your test “pyramid” will most likely look like a rectangle with an equal number of unit and integration tests and no end-to-end tests.
测试金字塔也有例外。例如,如果你的应用程序所做的只是基本的创建、读取、更新和删除(CRUD)操作,很少有业务规则或任何其他的复杂性,你的测试 “金字塔 “很可能看起来像一个矩形,有相同数量的单元和集成测试,没有端到端的测试。
Unit tests are less useful in a setting without algorithmic or business complexity— they quickly descend into trivial tests. At the same time, integration tests retain their value—it’s still important to verify how code, however simple it is, works in integration with other subsystems, such as the database. As a result, you may end up with fewer unit tests and more integration tests. In the most trivial examples, the number of integration tests may even be greater than the number of unit tests.
单元测试在没有算法或业务复杂性的情况下不太有用,它们很快就会沦为无足轻重的测试。同时,集成测试保留了它们的价值–验证代码(不管它有多简单)在与其他子系统(如数据库)的集成中如何工作仍然很重要。因此,你可能最终会减少单元测试而增加集成测试。在最无足轻重的例子中,集成测试的数量甚至可能大于单元测试的数量。
Another exception to the Test Pyramid is an API that reaches out to a single out-ofprocess dependency—say, a database. Having more end-to-end tests may be a viable option for such an application. Since there’s no user interface, end-to-end tests will run reasonably fast. The maintenance costs won’t be too high, either, because you only work with the single external dependency, the database. Basically, end-to-end tests are indistinguishable from integration tests in this environment. The only thing that differs is the entry point: end-to-end tests require the application to be hosted somewhere to fully emulate the end user, while integration tests normally host the application in the same process. We’ll get back to the Test Pyramid in chapter 8, when we’ll be talking about integration testing.
测试金字塔的另一个例外是 API,它访问单个进程外依赖项(例如数据库)。对于此类应用进程,拥有更多的端到端测试可能是一个可行的选择。由于没有用户界面,端到端测试的运行速度相当快。维护成本也不会太高,因为您只使用单个外部依赖项,即数据库。基本上,在这种环境中,端到端测试与集成测试没有区别。唯一不同的是入口点:端到端测试要求将应用进程托管在某个位置以完全模拟最终用户,而集成测试通常在同一进程中托管应用进程。我们将在第 8 章回到测试金字塔,届时我们将讨论集成测试。
4.5.2 在黑盒和白盒测试之间进行选择
Choosing between black-box and white-box testing
The other well-known test automation concept is black-box versus white-box testing. In this section, I show when to use each of the two approaches:
另一个著名的测试自动化概念是黑盒与白盒测试。在本节中,我将展示何时使用这两种方法中的每一种:
- Black-box testing is a method of software testing that examines the functionality of a system without knowing its internal structure. Such testing is normally built around specifications and requirements: what the application is supposed to do, rather than how it does it.
- 黑盒测试是一种软件测试方法,在不了解系统内部结构的情况下检查其功能。这种测试通常是围绕着规范和要求进行的:应用程序应该做什么,而不是它如何做。
- White-box testing is the opposite of that. It’s a method of testing that verifies the application’s inner workings. The tests are derived from the source code, not requirements or specifications.
- 白盒测试则与此相反。它是一种验证应用程序内部运作的测试方法。测试是来自于源代码,而不是需求或规范。
There are pros and cons to both of these methods. White-box testing tends to be more thorough. By analyzing the source code, you can uncover a lot of errors that you may miss when relying solely on external specifications. On the other hand, tests resulting from white-box testing are often brittle, as they tend to tightly couple to the specific implementation of the code under test. Such tests produce many false positives and thus fall short on the metric of resistance to refactoring. They also often can’t be traced back to a behavior that is meaningful to a business person, which is a strong sign that these tests are fragile and don’t add much value. Black-box testing provides the opposite set of pros and cons (table 4.1).
这两种方法各有利弊。白盒测试往往更彻底。通过分析源代码,您可以发现许多错误,这些错误在仅依赖外部规范时可能会遗漏。另一方面,由白盒测试产生的测试通常是脆弱的,因为它们往往与被测代码的特定实现紧密耦合。此类测试会产生许多假阳性,因此无法达到抵御重构的指标。它们通常也无法追溯到对业务人员有意义的行为,这是一个强烈的迹象,表明这些测试是脆弱的,不会增加太多价值。黑盒测试提供了相反的优点和缺点(表 4.1)。
Table 4.1 The pros and cons of white-box and black-box testing 表4.1 白盒和黑盒测试的优点和缺点
| Protection against regressions | Resistance to refactoring | |
|---|---|---|
| White-box testing | Good | Bad |
| Black-box testing | Bad | Good |
As you may remember from section 4.4.5, you can’t compromise on resistance to refactoring: a test either possesses resistance to refactoring or it doesn’t. Therefore, choose blackbox testing over white-box testing by default. Make all tests—be they unit, integration, or end-to-end—view the system as a black box and verify behavior meaningful to the problem domain. If you can’t trace a test back to a business requirement, it’s an indication of the test’s brittleness. Either restructure or delete this test; don’t let it into the suite as-is. The only exception is when the test covers utility code with high algorithmic complexity (more on this in chapter 7).
你可能还记得 4.4.5 节,你不能在抵御重构方面妥协:一个测试要么拥有抵御重构的能力,要么没有。因此,默认选择黑盒测试而不是白盒测试。让所有的测试–无论是单元测试、集成测试还是端到端测试–都把系统看作一个黑箱,并验证对问题领域有意义的行为。如果你不能把一个测试追溯到业务需求上,这就说明了测试的脆弱性。要么重组,要么删除这个测试;不要让它进入套件。唯一的例外是当测试涵盖了具有高算法复杂性的工具代码时(在第 7 章有更多的介绍)。
Note that even though black-box testing is preferable when writing tests, you can still use the white-box method when analyzing the tests. Use code coverage tools to see which code branches are not exercised, but then turn around and test them as if you know nothing about the code’s internal structure. Such a combination of the white-box and black-box methods works best.
请注意,尽管在编写测试时最好使用黑盒测试,但在分析测试时仍可以使用白盒方法。使用代码覆盖率工具查看哪些代码分支没有被执行,然后再来测试它们,就好像你对代码的内部结构一无所知一样。白盒和黑盒方法的这种组合效果最好。
总结
Summary
A good unit test has four foundational attributes that you can use to analyze any automated test, whether unit, integration, or end-to-end:
一个好的单元测试有四个基本属性,您可以用它们来分析任何自动测试,无论是单元测试、集成测试还是端到端测试:
- – Protection against regressions 防止回归
- – Resistance to refactoring 抵御重构
- – Fast feedback 快速反馈
- – Maintainability 可维护性
Protection against regressions is a measure of how good the test is at indicating the presence of bugs (regressions). The more code the test executes (both your code and the code of libraries and frameworks used in the project), the higher the chance this test will reveal a bug.
防止回归是衡量测试在显示 bug(回归)存在方面的能力。测试执行的代码越多(包括您的代码以及项目中使用的库和框架的代码),测试发现 bug 的几率就越高。
Resistance to refactoring is the degree to which a test can sustain application code refactoring without producing a false positive.
抵御重构是指测试能在不产生假阳性的情况下承受应用程序代码重构的程度。
A false positive is a false alarm—a result indicating that the test fails, whereas the functionality it covers works as intended. False positives can have a devastating effect on the test suite:
假阳性是一种误报–表明测试失败的结果,而测试所涵盖的功能却能正常工作。误报会对测试套件产生破坏性影响:
They dilute your ability and willingness to react to problems in code, because you get accustomed to false alarms and stop paying attention to them.
它们会削弱你对代码中的问题做出反应的能力和意愿,因为你已经习惯了错误警报,不再关注它们。
They diminish your perception of tests as a reliable safety net and lead to losing trust in the test suite.
它们会削弱你对测试作为可靠安全网的看法,导致你对测试套件失去信任。
False positives are a result of tight coupling between tests and the internal implementation details of the system under test. To avoid such coupling, the test must verify the end result the SUT produces, not the steps it took to do that.
假阳性是测试与被测系统内部实现细节紧密耦合的结果。为避免这种耦合,测试必须验证被测系统产生的最终结果,而不是实现该结果的步骤。
Protection against regressions and resistance to refactoring contribute to test accuracy. A test is accurate insofar as it generates a strong signal (is capable of finding bugs, the sphere of protection against regressions) with as little noise (false positives) as possible (the sphere of resistance to refactoring).
防止回归和抵御重构有助于提高测试的准确性。测试的准确性取决于它是否能产生强烈的信号(能够发现bug,即防止回归的保护范围)和尽可能少的噪音(假阳性)(抵御重构的范围)。
False positives don’t have as much of a negative effect in the beginning of the project, but they become increasingly important as the project grows: as important as false negatives (unnoticed bugs).
在项目初期,假阳性不会产生太大的负面影响,但随着项目的发展,假阳性会变得越来越重要:其重要性不亚于假阴性(未被发现的 bug)。
Fast feedback is a measure of how quickly the test executes.
快速反馈是对测试执行速度的衡量。
Maintainability consists of two components:
可维护性由两部分组成:
How hard it is to understand the test. The smaller the test, the more readable it is.
理解测试的难易程度。测试越小,可读性就越高。
How hard it is to run the test. The fewer out-of-process dependencies the test reaches out to, the easier it is to keep them operational.
运行测试的难度。测试所涉及的进程外依赖关系越少,就越容易保持它们的运行。
A test’s value estimate is the product of scores the test gets in each of the four attributes. If the test gets zero in one of the attributes, its value turns to zero as well.
测试的价值估计是测试在四个属性中得到的分数的乘积。如果测试在其中一个属性中得到零,那么它的价值也变为零。
It’s impossible to create a test that gets the maximum score in all four attributes, because the first three—protection against regressions, resistance to refactoring, and fast feedback—are mutually exclusive. The test can only maximize two out of the three.
不可能创建一个在所有四个属性中都能获得最高分的测试,因为前三个属性–防止回归、抵御重构和快速反馈–是相互排斥的。测试只能使三项中的两项达到最高分。
Resistance to refactoring is non-negotiable because whether a test possess this attribute is mostly a binary choice: the test either has resistance to refactoring or it doesn’t. The trade-off between the attributes comes down to the choice between protection against regressions and fast feedback.
抵御重构是不可协商的,因为测试是否具备这一属性主要是一个二元选择:测试要么具备抵御重构的能力,要么不具备。属性之间的权衡归根结底是在防止回归和快速反馈之间做出选择。
The Test Pyramid advocates for a certain ratio of unit, integration, and end-toend tests: end-to-end tests should be in the minority, unit tests in the majority, and integration tests somewhere in the middle.
测试金字塔主张单元测试、集成测试和端到端测试保持一定的比例:端到端测试应占少数,单元测试应占多数,集成测试应处于中间位置。
Different types of tests in the pyramid make different choices between fast feedback and protection against regressions. End-to-end tests favor protection against regressions, while unit tests favor fast feedback.
金字塔中不同类型的测试在快速反馈和防止回归之间做出了不同的选择。端到端测试倾向于防止回归,而单元测试倾向于快速反馈。
Use the black-box testing method when writing tests. Use the white-box method when analyzing the tests.
编写测试时使用黑盒测试方法。分析测试时使用白盒方法。