单元测试原则、实践与模式(六)
译者声明:本译文仅作为学习的记录,不作为任务商业用途,如有侵权请告知我删除。
本文禁止转载!
请支持原书正版:https://www.manning.com/books/unit-testing
第六章 单元测试的风格
Chapter 6 Styles of unit testing
This chapter covers 本章内容涵盖
- Comparing styles of unit testing 比较单元测试的风格
- The relationship between functional and hexagonal architectures 函数式架构和六边形架构之间的关系
- Transitioning to output-based testing 过渡到基于输出的测试
Chapter 4 introduced the four attributes of a good unit test: protection against regressions, resistance to refactoring, fast feedback, and maintainability. These attributes form a frame of reference that you can use to analyze specific tests and unit testing approaches. We analyzed one such approach in chapter 5: the use of mocks.
第 4 章介绍了一个好的单元测试的四个属性:防止回归,抵御重构,快速反馈,和可维护性。这些属性形成了一个参考框架,你可以用它来分析具体的测试和单元测试方法。我们在第 5 章中分析了这样一种方法:使用 mocks。
In this chapter, I apply the same frame of reference to the topic of unit testing styles. There are three such styles: output-based, state-based, and communication-based testing. Among the three, the output-based style produces tests of the highest quality, state-based testing is the second-best choice, and communication-based testing should be used only occasionally.
在本章中,我将同样的参考框架应用于单元测试风格的主题。有三种风格:基于输出、基于状态和基于交互的测试。在这三种风格中,基于输出的风格能产生最高质量的测试,基于状态的测试是第二好的选择,而基于交互的测试只应偶尔使用。
Unfortunately, you can’t use the output-based testing style everywhere. It’s only applicable to code written in a purely functional way. But don’t worry; there are techniques that can help you transform more of your tests into the output-based style. For that, you’ll need to use functional programming principles to restructure the underlying code toward a functional architecture.
不幸的是,你不能到处使用基于输出的测试风格。它只适用于以函数式编写的代码。但不要担心,有一些技术可以帮助你将更多的测试转化为基于输出的风格。为此,你需要使用函数式编程原则来重构底层代码,使其朝着函数式架构的方向发展。
Note that this chapter doesn’t provide a deep dive into the topic of functional programming. Still, by the end of this chapter, I hope you’ll have an intuitive understanding of how functional programming relates to output-based testing. You’ll also learn how to write more of your tests using the output-based style, as well as the limitations of functional programming and functional architecture.
请注意,本章并没有对函数式编程的主题进行深入探讨。不过,在本章结束时,我希望你能对函数式编程与基于输出的测试的关系有一个直观的了解。你还会学到如何使用基于输出的风格来编写更多的测试,以及函数式编程和函数式架构的局限性。
6.1 单元测试的三种风格
The three styles of unit testing
As I mentioned in the chapter introduction, there are three styles of unit testing:
正如我在本章介绍中提到的,有三种风格的单元测试:
- Output-based testing 基于输出的测试
- State-based testing 基于状态的测试
- Communication-based testing 基于交互的测试
You can employ one, two, or even all three styles together in a single test. This section lays the foundation for the whole chapter by defining (with examples) those three styles of unit testing. You’ll see how they score against each other in the section after that.
你可以在一个测试中采用一种、两种、甚至三种风格。本节通过定义这三种单元测试风格(有例子),为整章奠定了基础。在之后的章节中,你将看到它们是如何相互比较的。
6.1.1 定义基于输出的风格
Defining the output-based style
The first style of unit testing is the output-based style, where you feed an input to the system under test (SUT) and check the output it produces (figure 6.1). This style of unit testing is only applicable to code that doesn’t change a global or internal state, so the only component to verify is its return value.
单元测试的第一种风格是基于输出的风格,即向被测系统(SUT)提供一个输入,并检查其产生的输出(图6.1)。这种单元测试方式只适用于不改变全局或内部状态的代码,所以唯一需要验证的部分是其返回值。
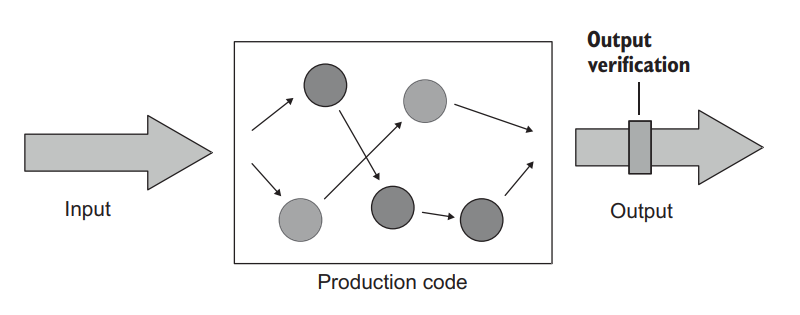
Figure 6.1 In output-based testing, tests verify the output the system generates. This style of testing assumes there are no side effects and the only result of the SUT’s work is the value it returns to the caller. 图6.1 在基于输出的测试中,测试验证系统产生的输出。这种测试方式假设没有副作用,SUT工作的唯一结果是它返回给调用者的值。
The following listing shows an example of such code and a test covering it. The PriceEngine class accepts an array of products and calculates a discount.
下面的列表显示了这种代码的一个例子和一个覆盖它的测试。PriceEngine 类接受一个产品数组,并计算出一个折扣。
Listing 6.1 Output-based testing 基于输出的测试
1 | public class PriceEngine |
PriceEngine multiplies the number of products by 1% and caps the result at 20%. There’s nothing else to this class. It doesn’t add the products to any internal collection, nor does it persist them in a database. The only outcome of the CalculateDiscount() method is the discount it returns: the output value (figure 6.2).
PriceEngine 将产品的数量乘以 1%,并将结果上限为 20%。这个类没有其他内容。它没有将产品添加到任何内部集合中,也没有将它们持久化在数据库中。CalculateDiscount() 方法的唯一结果是它返回的折扣:输出值(图6.2)。
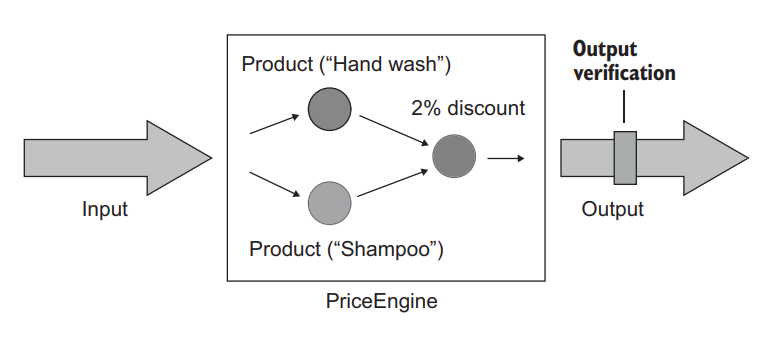
Figure 6.2 PriceEngine represented using input-output notation. Its CalculateDiscount() method accepts an array of products and calculates a discount. 图6.2 PriceEngine 使用输入输出符号表示。它的 CalculateDiscount() 方法接受一个产品数组,并计算出一个折扣。
The output-based style of unit testing is also known as functional. This name takes root in functional programming, a method of programming that emphasizes a preference for side-effect-free code. We’ll talk more about functional programming and functional architecture later in this chapter.
基于输出的单元测试风格也被称为函数式。这个名字源于函数式编程,一种强调无副作用的代码的编程方法。在本章后面,我们将更多地讨论函数式编程和函数式架构。
6.1.2 定义基于状态的风格
Defining the state-based style
The state-based style is about verifying the state of the system after an operation is complete (figure 6.3). The term state in this style of testing can refer to the state of the SUT itself, of one of its collaborators, or of an out-of-process dependency, such as the database or the filesystem.
基于状态的风格是在操作完成后验证系统的状态(图6.3)。这种测试方式中的状态一词可以指 SUT 本身的状态,也可以指它的一个合作者的状态,还可以指进程外的依赖关系,如数据库或文件系统。
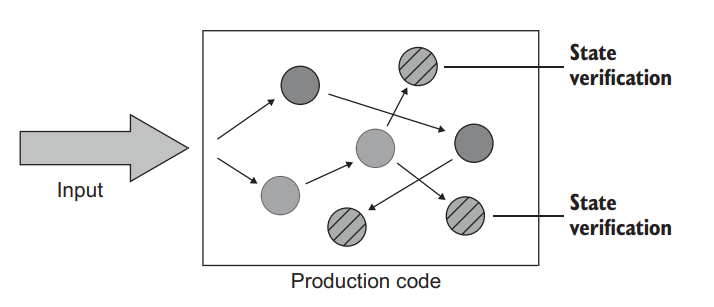
Figure 6.3 In state-based testing, tests verify the final state of the system after an operation is complete. The dashed circles represent that final state. 图6.3 在基于状态的测试中,测试验证操作完成后系统的最终状态。虚线圆圈代表最终状态。
Here’s an example of state-based testing. The Order class allows the client to add a new product.
下面是一个基于状态的测试的例子。订单类允许客户添加一个新产品。
Listing 6.2 State-based testing 基于状态的测试
1 | public class Order |
The test verifies the Products collection after the addition is completed. Unlike the example of output-based testing in listing 6.1, the outcome of AddProduct() is the change made to the order’s state.
该测试在添加完成后验证了 Products 集合。与清单 6.1 中基于输出的测试的例子不同,AddProduct() 的结果是对订单状态的改变。
6.1.3 Defining the communication-based style
Finally, the third style of unit testing is communication-based testing. This style uses mocks to verify communications between the system under test and its collaborators (figure 6.4).
最后,单元测试的第三种风格是基于交互的测试。这种风格使用 mock 来验证被测系统和其合作者之间的交互(图6.4)。
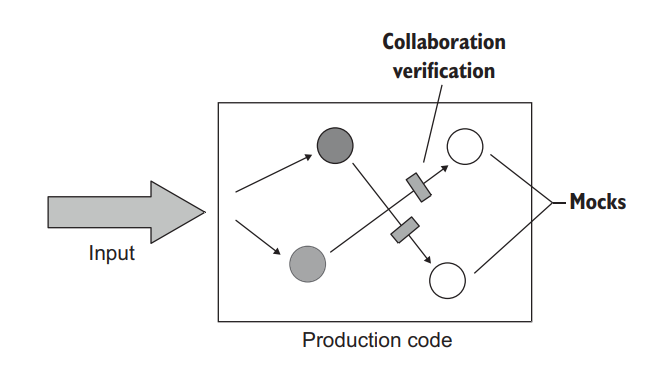
Figure 6.4 In communication-based testing, tests substitute the SUT’s collaborators with mocks and verify that the SUT calls those collaborators correctly. 图6.4 在基于交互的测试中,测试用 mock 来代替 SUT 的合作者,并验证 SUT 是否正确调用这些合作者。
The following listing shows an example of communication-based testing. 下面的清单显示了一个基于交互的测试的例子。
Listing 6.3 Communication-based testing 基于交互的测试
1 | [] |
Styles and schools of unit testing 单元测试的风格和流派
The classical school of unit testing prefers the state-based style over the communication-based one. The London school makes the opposite choice. Both schools use outputbased testing.
单元测试的经典学派更喜欢基于状态的风格而不是基于交互的风格。伦敦学派则做出了相反的选择。两个流派都使用基于输出的测试。
6.2 比较单元测试的三种风格
Comparing the three styles of unit testing
There’s nothing new about output-based, state-based, and communication-based styles of unit testing. In fact, you already saw all of these styles previously in this book. What’s interesting is comparing them to each other using the four attributes of a good unit test. Here are those attributes again (refer to chapter 4 for more details):
基于输出、基于状态和基于交互的单元测试风格并没有什么新意。事实上,你已经在本书中看到了所有这些风格。有趣的是用单元测试的四个属性将它们相互比较。下面是这些属性(更多细节请参考第四章):
- Protection against regressions 防止回归
- Resistance to refactoring 抵御重构
- Fast feedback 快速反馈
- Maintainability 可维护性
In our comparison, let’s look at each of the four separately.
在我们的比较中,让我们分别看一下这四个属性。
6.2.1 使用防止回归和反馈速度的指标来比较这些风格
Comparing the styles using the metrics of protection against regressions and feedback speed
Let’s first compare the three styles in terms of the protection against regressions and feedback speed attributes, as these attributes are the most straightforward in this particular comparison. The metric of protection against regressions doesn’t depend on a particular style of testing. This metric is a product of the following three characteristics:
让我们首先从防止回归和反馈速度的属性来比较这三种风格,因为这些属性在这个特定的比较中是最直接的。对防止回归的指标并不取决于特定的测试风格。这个指标是以下三个特征的产物:
- The amount of code that is executed during the test 测试过程中执行的代码量
- The complexity of that code 该代码的复杂性
- Its domain significance 其领域的重要性
Generally, you can write a test that exercises as much or as little code as you like; no particular style provides a benefit in this area. The same is true for the code’s complexity and domain significance. The only exception is the communication-based style: overusing it can result in shallow tests that verify only a thin slice of code and mock out everything else. Such shallowness is not a definitive feature of communicationbased testing, though, but rather is an extreme case of abusing this technique.
一般来说,你可以写一个测试,只要你喜欢,就可以执行更多或更少的代码;在这个领域没有特定的风格提供好处。对于代码的复杂性和领域重要性也是如此。唯一的例外是基于交互的风格:过度使用它可能会导致浅层的测试,只验证代码的一个薄片,而模拟出其他的一切。不过,这种浅薄并不是基于交互的测试的明确特征,而是滥用这种技术的极端情况。
There’s little correlation between the styles of testing and the test’s feedback speed. As long as your tests don’t touch out-of-process dependencies and thus stay in the realm of unit testing, all styles produce tests of roughly equal speed of execution. Communication-based testing can be slightly worse because mocks tend to introduce additional latency at runtime. But the difference is negligible, unless you have tens of thousands of such tests.
测试的风格和测试的反馈速度之间没有什么关联。只要你的测试不接触进程外的依赖关系,从而保持在单元测试的范围内,所有的风格产生的测试的执行速度大致相同。基于交互的测试可能会稍微差一点,因为模拟往往会在运行时引入额外的延迟。但是,除非你有数以万计的此类测试,否则这种差异是可以忽略不计的。
6.2.2 使用抵御重构来比较这些风格
Comparing the styles using the metric of resistance to refactoring
When it comes to the metric of resistance to refactoring, the situation is different. Resistance to refactoring is the measure of how many false positives (false alarms) tests generate during refactorings. False positives, in turn, are a result of tests coupling to code’s implementation details as opposed to observable behavior.
当涉及到抵御重构的指标时,情况就不同了。抵御重构是衡量测试在重构过程中产生多少假阳性(假警报)。反过来,假阳性是测试与代码的实现细节相耦合的结果,而不是可观察的行为。
Output-based testing provides the best protection against false positives because the resulting tests couple only to the method under test. The only way for such tests to couple to implementation details is when the method under test is itself an implementation detail.
基于输出的测试对假阳性提供了最好的保护,因为所产生的测试只与被测方法耦合。这种测试耦合到实现细节的唯一方法是被测方法本身就是一个实现细节。
State-based testing is usually more prone to false positives. In addition to the method under test, such tests also work with the class’s state. Probabilistically speaking, the greater the coupling between the test and the production code, the greater the chance for this test to tie to a leaking implementation detail. State-based tests tie to a larger API surface, and hence the chances of coupling them to implementation details are also higher.
基于状态的测试通常更容易出现假阳性。除了被测方法之外,这种测试还与类的状态一起工作。从概率上讲,测试和生产代码之间的耦合度越大,这个测试与暴露的实现细节相关的机会就越大。基于状态的测试绑定到更大的 API 平面,因此将它们耦合到实现细节的可能性也更高。
Communication-based testing is the most vulnerable to false alarms. As you may remember from chapter 5, the vast majority of tests that check interactions with test doubles end up being brittle. This is always the case for interactions with stubs—you should never check such interactions. Mocks are fine only when they verify interactions that cross the application boundary and only when the side effects of those interactions are visible to the external world. As you can see, using communicationbased testing requires extra prudence in order to maintain proper resistance to refactoring.
基于交互的测试是最容易出现假警报的。你可能还记得第五章,绝大多数检查与测试替身的交互的测试最终都很脆弱。与存根的交互也是如此–你不应该检查这种交互。只有在验证跨越应用边界的交互时,以及只有在这些交互的副作用对外部世界可见时,Mocks 才是好的。正如你所看到的,使用基于交互的测试需要额外的谨慎,以保持适当抵御重构。
But just like shallowness, brittleness is not a definitive feature of the communicationbased style, either. You can reduce the number of false positives to a minimum by maintaining proper encapsulation and coupling tests to observable behavior only. Admittedly, though, the amount of due diligence varies depending on the style of unit testing.
但就像浅薄一样,脆弱也不是基于交互的风格的明确特征。你可以通过保持适当的封装和将测试与可观察到的行为耦合起来,将假阳性的数量降到最低。诚然,尽管单元测试的风格不同,尽职尽责的程度也不同。
6.2.3 使用可维护性指标来比较这些风格
Comparing the styles using the metric of maintainability
Finally, the maintainability metric is highly correlated with the styles of unit testing; but, unlike with resistance to refactoring, there’s not much you can do to mitigate that. Maintainability evaluates the unit tests’ maintenance costs and is defined by the following two characteristics:
最后,可维护性指标与单元测试的风格高度相关;但是,与抵御重构不同的是,你没有什么办法来缓解这种情况。可维护性评估了单元测试的维护成本,由以下两个特征定义:
- How hard it is to understand the test, which is a function of the test’s size 理解测试有多难,这是测试规模的一个函数。
- How hard it is to run the test, which is a function of how many out-of-process dependencies the test works with directly 运行测试有多难,这是测试直接与多少进程外的依赖关系的函数
Larger tests are less maintainable because they are harder to grasp or change when needed. Similarly, a test that directly works with one or several out-of-process dependencies (such as the database) is less maintainable because you need to spend time keeping those out-of-process dependencies operational: rebooting the database server, resolving network connectivity issues, and so on.
较大的测试可维护性较差,因为它们在需要时更难掌握或改变。同样,一个直接与一个或几个进程外依赖关系(如数据库)工作的测试的可维护性也较差,因为你需要花时间保持这些进程外依赖关系的运行:重新启动数据库服务器,解决网络连接问题,等等。
基于输出的测试的可维护性
MAINTAINABILITY OF OUTPUT-BASED TESTS
Compared with the other two types of testing, output-based testing is the most maintainable. The resulting tests are almost always short and concise and thus are easier to maintain. This benefit of the output-based style stems from the fact that this style boils down to only two things: supplying an input to a method and verifying its output, which you can often do with just a couple lines of code.
与其他两种类型的测试相比,基于输出的测试是最容易维护的。所产生的测试几乎都是短小精悍的,因此更容易维护。基于输出的风格的这一好处源于这样一个事实,即这种风格只归结为两件事:向方法提供输入并验证其输出,你通常只需用几行代码就可以做到。
Because the underlying code in output-based testing must not change the global or internal state, these tests don’t deal with out-of-process dependencies. Hence, output-based tests are best in terms of both maintainability characteristics.
因为基于输出的测试的底层代码不能改变全局或内部状态,这些测试不处理进程外的依赖关系。因此,基于输出的测试在这两个可维护性特征方面是最好的。
基于状态的测试的可维护性
MAINTAINABILITY OF STATE-BASED TESTS
State-based tests are normally less maintainable than output-based ones. This is because state verification often takes up more space than output verification. Here’s another example of state-based testing.
基于状态的测试通常比基于输出的测试可维护性要差。这是因为状态验证往往比输出验证占用更多的空间。下面是另一个基于状态的测试的例子。
Listing 6.4 State verification that takes up a lot of space 占用大量空间的状态验证
1 | [] |
This test adds a comment to an article and then checks to see if the comment appears in the article’s list of comments. Although this test is simplified and contains just a single comment, its assertion part already spans four lines. State-based tests often need to verify much more data than that and, therefore, can grow in size significantly.
这个测试在一篇文章中添加一个评论,然后检查该评论是否出现在文章的评论列表中。虽然这个测试是简化的,只包含一个评论,但其断言部分已经跨越了四行。基于状态的测试经常需要验证比这多得多的数据,因此,规模会大大增加。
You can mitigate this issue by introducing helper methods that hide most of the code and thus shorten the test (see listing 6.5), but these methods require significant effort to write and maintain. This effort is justified only when those methods are going to be reused across multiple tests, which is rarely the case. I’ll explain more about helper methods in part 3 of this book.
你可以通过引入隐藏大部分代码的辅助方法来缓解这个问题,从而缩短测试(见列表6.5),但是这些方法需要花费大量的精力来编写和维护。只有当这些方法要在多个测试中重复使用时,这种努力才是合理的,但这种情况很少。我将在本书的第三部分解释更多关于辅助方法的内容。
Listing 6.5 Using helper methods in assertions 在断言中使用辅助方法
1 | [] |
Another way to shorten a state-based test is to define equality members in the class that is being asserted. In listing 6.6, that’s the Comment class. You could turn it into a value object (a class whose instances are compared by value and not by reference), as shown next; this would also simplify the test, especially if you combined it with an assertion library like Fluent Assertions.
另一种缩短基于状态的测试的方法是在被断言的类中定义平等成员。在列表 6.6 中,那是 Comment 类。你可以把它变成一个值对象(一个实例通过值而不是引用进行比较的类),如下所示;这也会简化测试,特别是如果你把它和一个像 Fluent Assertions 这样的断言库结合起来。
Listing 6.6 Comment compared by value 按值比较的评论
1 | [] |
This test uses the fact that comments can be compared as whole values, without the need to assert individual properties in them. It also uses the BeEquivalentTo method from Fluent Assertions, which can compare entire collections, thereby removing the need to check the collection size.
这个测试使用了这样一个事实:评论可以作为整个值进行比较,而不需要对其中的单个属性进行断言。它还使用了 Fluent Assertions 中的 BeEquivalentTo 方法,该方法可以比较整个集合,从而不需要检查集合的大小。
This is a powerful technique, but it works only when the class is inherently a value and can be converted into a value object. Otherwise, it leads to code pollution (polluting production code base with code whose sole purpose is to enable or, as in this case, simplify unit testing). We’ll discuss code pollution along with other unit testing antipatterns in chapter 11.
这是一个强大的技术,但它只在类本身是一个值并且可以被转换为一个值对象时才有效。否则,它会导致代码污染(用代码污染生产代码库,其唯一目的是启用或(如本例中)简化单元测试)。我们将在第 11 章讨论代码污染和其他单元测试反模式。
As you can see, these two techniques—using helper methods and converting classes into value objects—are applicable only occasionally. And even when these techniques are applicable, state-based tests still take up more space than output-based tests and thus remain less maintainable.
正如你所看到的,这两种技术–使用辅助方法和将类转换为值对象–只是偶尔适用。即使这些技术适用,基于状态的测试仍然比基于输出的测试占用更多的空间,因此仍然不具有可维护性。
基于交互的测试的可维护性
MAINTAINABILITY OF COMMUNICATION-BASED TESTS
Communication-based tests score worse than output-based and state-based tests on the maintainability metric. Communication-based testing requires setting up test doubles and interaction assertions, and that takes up a lot of space. Tests become even larger and less maintainable when you have mock chains (mocks or stubs returning other mocks, which also return mocks, and so on, several layers deep).
在可维护性指标上,基于交互的测试比基于输出和基于状态的测试得分更低。基于交互的测试需要设置测试替身和交互断言,这就占用了大量的空间。当你有模拟链(模拟或存根返回其他模拟,而其他模拟也返回模拟,以此类推,深达数层)时,测试变得更大,更难维护。
6.2.4 风格对比:结果
Comparing the styles: The results
Let’s now compare the styles of unit testing using the attributes of a good unit test. Table 6.1 sums up the comparison results. As discussed in section 6.2.1, all three styles score equally with the metrics of protection against regressions and feedback speed; hence, I’m omitting these metrics from the comparison.
现在让我们用一个好的单元测试的属性来比较单元测试的风格。表 6.1 总结了比较的结果。正如在第 6.2.1 节中所讨论的,所有三种风格在防止回归和反馈速度的指标上得分相同;因此,我在比较中略去了这些指标。
Output-based testing shows the best results. This style produces tests that rarely couple to implementation details and thus don’t require much due diligence to maintain proper resistance to refactoring. Such tests are also the most maintainable due to their conciseness and lack of out-of-process dependencies.
基于输出的测试显示了最好的结果。这种风格产生的测试很少与实现细节相联系,因此不需要太多的尽职调查来保持对重构的适当抵抗。这样的测试也是最容易维护的,因为它们的简洁性和缺乏进程外的依赖性。
Table 6.1 The three styles of unit testing: The comparisons 单元测试的三种风格:比较
| Output-based | State-based | Communication-based | |
|---|---|---|---|
| Due diligence to maintain resistance to refactoring | Low | Medium | Medium |
| Maintainability costs | Low | Medium | High |
State-based and communication-based tests are worse on both metrics. These are more likely to couple to a leaking implementation detail, and they also incur higher maintenance costs due to being larger in size.
基于状态和交互的测试在这两个指标上都比较差。这些测试更有可能耦合到泄漏的实现细节上,而且由于规模较大,它们的维护成本也较高。
Always prefer output-based testing over everything else. Unfortunately, it’s easier said than done. This style of unit testing is only applicable to code that is written in a functional way, which is rarely the case for most object-oriented programming languages. Still, there are techniques you can use to transition more of your tests toward the output-based style.
总是倾向于基于输出的测试,而不是其他的。不幸的是,这说起来容易,做起来难。这种单元测试的风格只适用于以函数方式编写的代码,对于大多数面向对象的编程语言来说,很少有这种情况。尽管如此,还是有一些技术可以用来将更多的测试过渡到基于输出的风格。
The rest of this chapter shows how to transition from state-based and collaborationbased testing to output-based testing. The transition requires you to make your code more purely functional, which, in turn, enables the use of output-based tests instead of state- or communication-based ones.
本章的其余部分展示了如何从基于状态和交互的测试过渡到基于输出的测试。这种过渡要求你使你的代码更加纯粹的函数化,这反过来又使你能够使用基于输出的测试而不是基于状态或交互的测试。
6.3 理解函数式架构
Understanding functional architecture
Some groundwork is needed before I can show how to make the transition. In this section, you’ll see what functional programming and functional architecture are and how the latter relates to the hexagonal architecture. Section 6.4 illustrates the transition using an example.
在我展示如何进行过渡之前,需要做一些基础工作。在本节中,你将看到什么是函数式编程和函数式架构,以及后者与六边形架构的关系。第 6.4 节用一个例子来说明这种过渡。
Note that this isn’t a deep dive into the topic of functional programming, but rather an explanation of the basic principles behind it. These basic principles should be enough to understand the connection between functional programming and output-based testing. For a deeper look at functional programming, see Scott Wlaschin’s website and books at https://fsharpforfunandprofit.com/books.
请注意,这并不是对函数式编程主题的深入探讨,而是对其背后的基本原则的解释。这些基本原则应该足以理解函数式编程和基于输出的测试之间的联系。要深入了解函数式编程,请参见 Scott Wlaschin 的网站和书籍:https://fsharpforfunandprofit.com/books。
6.3.1 什么是函数式编程
What is functional programming?
As I mentioned in section 6.1.1, the output-based unit testing style is also known as functional. That’s because it requires the underlying production code to be written in a purely functional way, using functional programming. So, what is functional programming?
正如我在第 6.1.1 节提到的,基于输出的单元测试风格也被称为函数式。这是因为它要求底层生产代码以纯粹的函数式方式编写,使用函数式编程。那么,什么是函数式编程?
Functional programming is programming with mathematical functions. A mathematical function (also known as pure function) is a function (or method) that doesn’t have any hidden inputs or outputs. All inputs and outputs of a mathematical function must be explicitly expressed in its method signature, which consists of the method’s name, arguments, and return type. A mathematical function produces the same output for a given input regardless of how many times it is called.
函数式编程是用数学函数编程。数学函数(也被称为纯函数)是一个没有任何隐藏输入或输出的函数(或方法)。数学函数的所有输入和输出都必须在其方法签名中明确表达,该签名由方法的名称、参数和返回类型组成。一个数学函数对一个给定的输入产生相同的输出,无论它被调用多少次。
Let’s take the CalculateDiscount() method from listing 6.1 as an example (I’m copying it here for convenience):
让我们以清单 6.1 中的 CalculateDiscount() 方法为例(为了方便起见,我将其复制到这里):
1 | public decimal CalculateDiscount(Product[] products) |
This method has one input (a Product array) and one output (the decimal discount), both of which are explicitly expressed in the method’s signature. There are no hidden inputs or outputs. This makes CalculateDiscount() a mathematical function (figure 6.5)
这个方法有一个输入(Product数组)和一个输出(小数折扣),这两个都在方法的签名中明确表达了。没有隐藏的输入或输出。这使得 CalculateDiscount() 成为一个数学函数(图6.5)
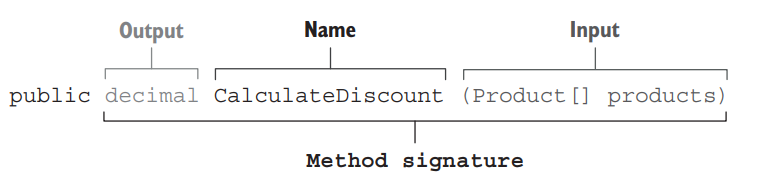
Figure 6.5 CalculateDiscount() has one input (a Product array) and one output (the decimal discount). Both the input and the output are explicitly expressed in the method’s signature, which makes CalculateDiscount() a mathematical function. 图6.5 CalculateDiscount() 有一个输入(一个产品数组)和一个输出(小数折扣)。输入和输出都在方法的签名中明确表达,这使得 CalculateDiscount() 成为一个数学函数。
Methods with no hidden inputs and outputs are called mathematical functions because such methods adhere to the definition of a function in mathematics.
没有隐藏输入和输出的方法被称为数学函数,因为这种方法符合数学中的函数定义。
DEFINITION
In mathematics, a function is a relationship between two sets that for each element in the first set, finds exactly one element in the second set.
在数学中,函数是两个集合之间的关系,对于第一个集合中的每个元素,在第二个集合中正好找到一个元素。
Figure 6.6 shows how for each input number x, function f(x) = x + 1 finds a corresponding number y. Figure 6.7 displays the CalculateDiscount() method using the same notation as in figure 6.6.
图 6.6 显示了对于每个输入的数字 x,函数 f(x)=x+1 如何找到一个相应的数字 y。图 6.7 使用与图 6.6 相同的符号显示了 CalculateDiscount() 方法。
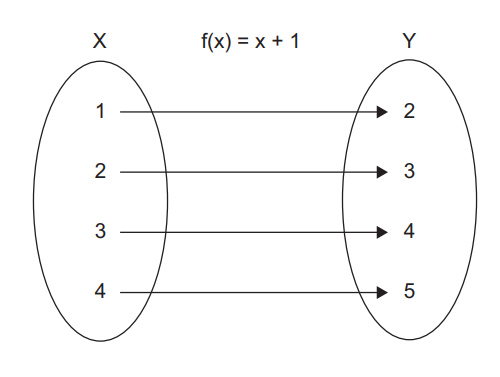
Figure 6.6 A typical example of a function in mathematics is f(x) = x + 1. For each input number x in set X, the function finds a corresponding number y in set Y. 图 6.6 数学中函数的一个典型例子是 f(x) = x + 1。对于集合 X 中的每个输入数字 x,该函数在集合 Y 中找到一个相应的数字 y。
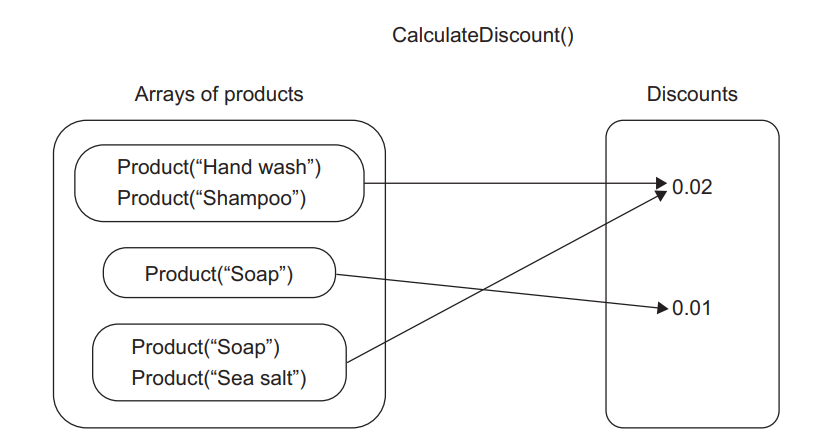
Figure 6.7 The CalculateDiscount() method represented using the same notation as the function f(x) = x + 1. For each input array of products, the method finds a corresponding discount as an output. 图 6.7 CalculateDiscount() 方法使用与函数 f(x) = x + 1 相同的符号表示。对于每个输入的产品数组,该方法都会找到一个相应的折扣作为输出。
Explicit inputs and outputs make mathematical functions extremely testable because the resulting tests are short, simple, and easy to understand and maintain. Mathematical functions are the only type of methods where you can apply output-based testing, which has the best maintainability and the lowest chance of producing a false positive.
明确的输入和输出使得数学函数具有极强的可测试性,因为所产生的测试很短,很简单,而且容易理解和维护。数学函数是唯一一种可以应用基于输出的测试的方法,它的可维护性最好,产生假阳性的几率最低。
On the other hand, hidden inputs and outputs make the code less testable (and less readable, too). Types of such hidden inputs and outputs include the following:
另一方面,隐藏的输入和输出使代码的可测试性降低(可读性也降低)。这种隐藏的输入和输出的类型包括以下内容:
Side effects—A side effect is an output that isn’t expressed in the method signature and, therefore, is hidden. An operation creates a side effect when it mutates the state of a class instance, updates a file on the disk, and so on.
副作用–副作用是一种在方法签名中没有表达的输出,因此是隐藏的。当一个操作改变了一个类实例的状态,更新了磁盘上的一个文件,等等,都会产生副作用。
Exceptions—When a method throws an exception, it creates a path in the program flow that bypasses the contract established by the method’s signature. The thrown exception can be caught anywhere in the call stack, thus introducing an additional output that the method signature doesn’t convey.
异常–当一个方法抛出一个异常时,它在程序流中创建了一个路径,绕过了方法签名所建立的契约。抛出的异常可以在调用堆栈的任何地方被捕获,从而引入了一个方法签名没有表达的额外输出。
A reference to an internal or external state—For example, a method can get the current date and time using a static property such as DateTime.Now. It can query data from the database, or it can refer to a private mutable field. These are all inputs to the execution flow that aren’t present in the method signature and, therefore, are hidden.
对内部或外部状态的引用例如,一个方法可以使用一个静态属性(如 DateTime.Now )来获得当前的日期和时间。它可以从数据库中查询数据,也可以引用一个私有的可变字段。这些都是执行流程的输入,在方法签名中没有出现,因此是隐藏的。
A good rule of thumb when determining whether a method is a mathematical function is to see if you can replace a call to that method with its return value without changing the program’s behavior. The ability to replace a method call with the corresponding value is known as referential transparency. Look at the following method, for example:
在确定一个方法是否是一个数学函数时,一个好的经验法则是看你是否能在不改变程序行为的情况下用其返回值来替换对该方法的调用。用相应的值替换方法调用的能力被称为参考透明度。例如,请看下面这个方法:
1 | public int Increment(int x) |
This method is a mathematical function. These two statements are equivalent to each other:
这个方法是一种数学函数。这两条语句是相互等价的:
1 | int y = Increment(4); |
On the other hand, the following method is not a mathematical function. You can’t replace it with the return value because that return value doesn’t represent all of the method’s outputs. In this example, the hidden output is the change to field x (a side effect):
另一方面,下面这个方法不是一个数学函数。你不能用返回值来代替它,因为这个返回值并不代表该方法的所有输出。在这个例子中,隐藏的输出是字段 x 的变化(一个副作用):
1 | int x = 0; |
Side effects are the most prevalent type of hidden outputs. The following listing shows an AddComment method that looks like a mathematical function on the surface but actually isn’t one. Figure 6.8 shows the method graphically.
副作用是最普遍的隐藏输出类型。下面的列表显示了一个 AddComment 方法,它表面上看起来像一个数学函数,但实际上并不是。图 6.8 以图形方式显示了这个方法。
Listing 6.7 Modification of an internal state 修改内部状态
1 | public Comment AddComment(string text) |
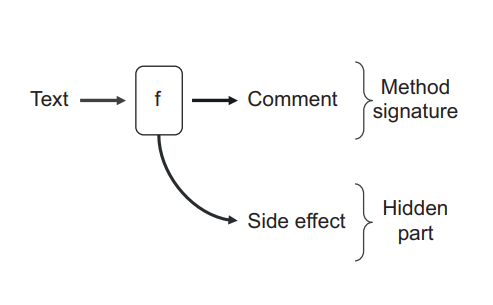
Figure 6.8 Method AddComment (shown as f) has a text input and a Comment output, which are both expressed in the method signature. The side effect is an additional hidden output. 图 6.8 方法 AddComment(显示为 f)有一个文本输入和一个 Comment 输出,它们都在方法签名中表达。副作用是一个额外的隐藏输出。
6.3.2 什么是函数式架构?
What is functional architecture?
You can’t create an application that doesn’t incur any side effects whatsoever, of course. Such an application would be impractical. After all, side effects are what you create all applications for: updating the user’s information, adding a new order line to the shopping cart, and so on.
当然,你不可能创建一个不产生任何副作用的应用程序。这样的应用将是不切实际的。毕竟,副作用是你创建所有应用程序的目的:更新用户的信息,在购物车中添加一个新的订单行,等等。
The goal of functional programming is not to eliminate side effects altogether but rather to introduce a separation between code that handles business logic and code that incurs side effects. These two responsibilities are complex enough on their own; mixing them together multiplies the complexity and hinders code maintainability in the long run. This is where functional architecture comes into play. It separates business logic from side effects by pushing those side effects to the edges of a business operation.
函数式编程的目标不是要完全消除副作用,而是要在处理业务逻辑的代码和产生副作用的代码之间引入分离。这两个职责本身就够复杂的了;把它们混在一起,从长远来看,会使复杂性成倍增加,并阻碍代码的可维护性。这就是函数式架构发挥作用的地方。它将业务逻辑与副作用分开,将这些副作用推到业务操作的边缘。
DEFINITION
Functional architecture maximizes the amount of code written in a purely functional (immutable) way, while minimizing code that deals with side effects. Immutable means unchangeable: once an object is created, its state can’t be modified. This is in contrast to a mutable object (changeable object), which can be modified after it is created.
函数式架构最大限度地增加了以纯功能(不可变)方式编写的代码量,同时最大限度地减少了处理副作用的代码。不可变的意思是不可改变的:一旦一个对象被创建,它的状态就不能被修改。这与可变对象(changeable object)形成对比,后者在创建后可以被修改。
The separation between business logic and side effects is done by segregating two types of code:
业务逻辑和副作用之间的分离是通过隔离两种类型的代码来实现的:
Code that makes a decision—This code doesn’t require side effects and thus can be written using mathematical functions.
做出决策的代码–这种代码不需要副作用,因此可以使用数学函数编写。
Code that acts upon that decision—This code converts all the decisions made by the mathematical functions into visible bits, such as changes in the database or messages sent to a bus.
对决策采取行动的代码–这种代码将数学函数做出的所有决策转化为可见的比特,如数据库中的变化或发送到总线上的消息。
The code that makes decisions is often referred to as a functional core (also known as an immutable core). The code that acts upon those decisions is a mutable shell (figure 6.9).
做出决策的代码通常被称为功能核心(也被称为不可变的核心)。对这些决策采取行动的代码是一个可变的外壳(图6.9)。
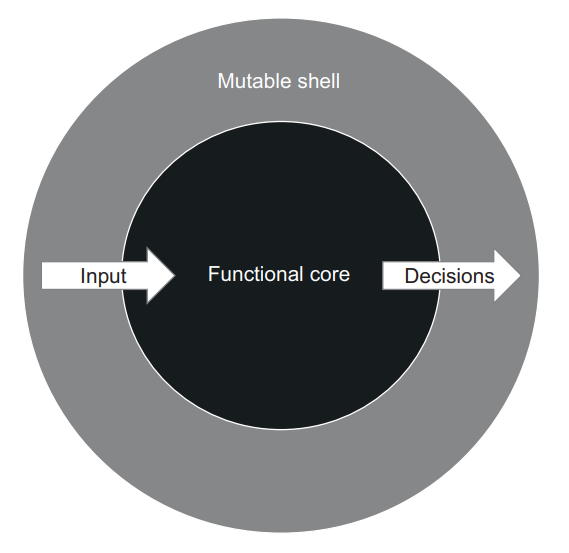
Figure 6.9 In functional architecture, the functional core is implemented using mathematical functions and makes all decisions in the application. The mutable shell provides the functional core with input data and interprets its decisions by applying side effects to out-of-process dependencies such as a database. 图6.9 在函数式架构中,函数式核心使用数学函数实现,并在应用程序中做出所有决策。可变外壳为功能核心提供输入数据,并通过对进程外的依赖关系(如数据库)应用副作用来解释其决策。
The functional core and the mutable shell cooperate in the following way:
功能核心和可变外壳以下列方式合作:
The mutable shell gathers all the inputs.
可变的外壳收集所有的输入。
The functional core generates decisions.
功能核心产生决策。
The shell converts the decisions into side effects. To maintain a proper separation between these two layers, you need to make sure the classes representing the decisions contain enough information for the mutable shell to act upon them without additional decision-making. In other words, the mutable shell should be as dumb as possible. The goal is to cover the functional core extensively with output-based tests and leave the mutable shell to a much smaller number of integration tests.
外壳将决策转换为副作用。为了在这两层之间保持适当的分离,你需要确保代表决策的类包含足够的信息,以便可变的外壳在没有额外决策的情况下对它们采取行动。换句话说,易变的外壳应该是尽可能的愚蠢。我们的目标是用基于输出的测试广泛地覆盖功能核心,并把可变的外壳留给数量少得多的集成测试。
Encapsulation and immutability 封装与不变性
Like encapsulation, functional architecture (in general) and immutability (in particular) serve the same goal as unit testing: enabling sustainable growth of your software project. In fact, there’s a deep connection between the concepts of encapsulation and immutability.
像封装一样,函数式架构(一般)和不变性(特别)与单元测试的目标相同:使你的软件项目持续增长。事实上,封装和不可变性这两个概念之间有很深的联系。
As you may remember from chapter 5, encapsulation is the act of protecting your code against inconsistencies. Encapsulation safeguards the class’s internals from corruption by
你可能还记得第五章,封装是保护你的代码不受不一致影响的行为。封装通过以下方式保护类的内部结构不被破坏
Reducing the API surface area that allows for data modification
减少允许数据修改的 API 范围
Putting the remaining APIs under scrutiny
将其余的 API 置于监督之下
Immutability tackles this issue of preserving invariants from another angle. With immutable classes, you don’t need to worry about state corruption because it’s impossible to corrupt something that cannot be changed in the first place. As a consequence, there’s no need for encapsulation in functional programming. You only need to validate the class’s state once, when you create an instance of it. After that, you can freely pass this instance around. When all your data is immutable, the whole set of issues related to the lack of encapsulation simply vanishes.
不可变性从另一个角度解决了保存不变量的问题。有了不可变的类,你就不需要担心状态的破坏,因为首先不可能破坏那些不能被改变的东西。因此,在函数式编程中没有必要进行封装。你只需要在创建一个类的实例时验证该类的状态一次。之后,你可以自由地传递这个实例。当你的所有数据都是不可变的,与缺乏封装有关的一系列问题就会消失。
There’s a great quote from Michael Feathers in that regard:
在这方面,Michael Feathers 有一句话说得很好:
Object-oriented programming makes code understandable by encapsulating moving parts. Functional programming makes code understandable by minimizing moving parts.
面向对象的编程通过封装活动部件使代码变得易懂。函数式编程通过最小化活动部件使代码变得易懂。
6.3.3 比较函数式架构和六边形架构
Comparing functional and hexagonal architectures
There are a lot of similarities between functional and hexagonal architectures. Both of them are built around the idea of separation of concerns. The details of that separation vary, though.
函数式架构和六边形架构之间有很多相似之处。它们都是围绕着关注点分离的理念而建立的。不过,这种分离的细节有所不同。
As you may remember from chapter 5, the hexagonal architecture differentiates the domain layer and the application services layer (figure 6.10). The domain layer is accountable for business logic while the application services layer, for communication with external applications such as a database or an SMTP service. This is very similar to functional architecture, where you introduce the separation of decisions and actions
你可能还记得第五章,六边形架构区分了领域层和应用服务层(图6.10)。领域层负责业务逻辑,而应用服务层则负责与外部应用程序(如数据库或 SMTP 服务)的通信。这与函数式架构非常相似,在这里你引入了决策和行动的分离
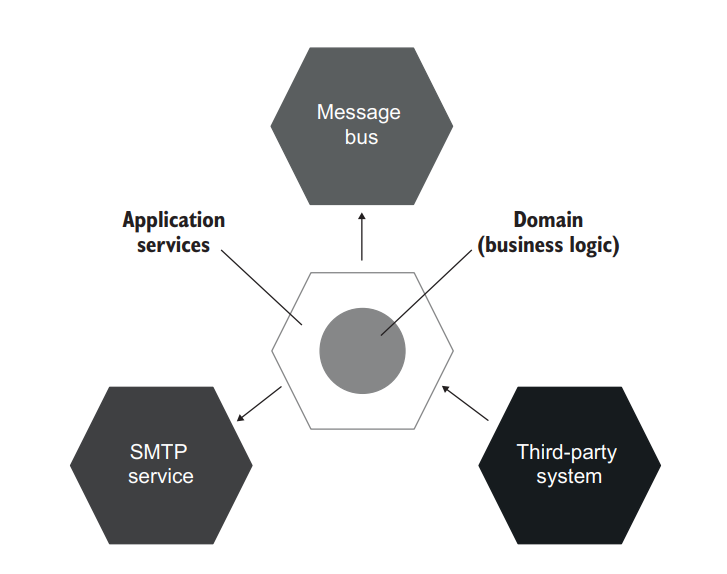
Figure 6.10 Hexagonal architecture is a set of interacting applications—hexagons. Your application consists of a domain layer and an application services layer, which correspond to a functional core and a mutable shell in functional architecture. 图 6.10 六边形架构是一组相互作用的应用程序–六边形。你的应用程序包括一个领域层和一个应用服务层,它们对应于函数式架构中的功能核心和可变外壳。
Another similarity is the one-way flow of dependencies. In the hexagonal architecture, classes inside the domain layer should only depend on each other; they should not depend on classes from the application services layer. Likewise, the immutable core in functional architecture doesn’t depend on the mutable shell. It’s self-sufficient and can work in isolation from the outer layers. This is what makes functional architecture so testable: you can strip the immutable core from the mutable shell entirely and simulate the inputs that the shell provides using simple values.
另一个相似之处是依赖关系的单向流动。在六边形架构中,领域层内的类只应相互依赖;它们不应依赖应用服务层的类。同样,函数式架构中的不可变的核心也不依赖于可变的外壳。它是自给自足的,可以在与外层隔离的情况下工作。这就是函数式架构的可测试性:你可以把不可变的核心从可变的外壳中完全剥离出来,用简单的值模拟外壳提供的输入。
The difference between the two is in their treatment of side effects. Functional architecture pushes all side effects out of the immutable core to the edges of a business operation. These edges are handled by the mutable shell. On the other hand, the hexagonal architecture is fine with side effects made by the domain layer, as long as they are limited to that domain layer only. All modifications in hexagonal architecture should be contained within the domain layer and not cross that layer’s boundary. For example, a domain class instance can’t persist something to the database directly, but it can change its own state. An application service will then pick up this change and apply it to the database.
两者之间的区别在于它们对副作用的处理。函数式架构将所有的副作用从不可变的核心推到业务操作的边缘。这些边缘由可变的外壳来处理。另一方面,六边形架构对领域层产生的副作用没有问题,只要它们只限于该领域层。六边形架构中的所有修改都应该包含在领域层中,而不是跨越该层的边界。例如,一个域类实例不能直接向数据库持久化一些东西,但它可以改变自己的状态。然后,一个应用服务将接收这个变化并将其应用到数据库中。
NOTE
Functional architecture is a subset of the hexagonal architecture. You can view functional architecture as the hexagonal architecture taken to an extreme.
函数式架构是六边形架构的一个子集。你可以把函数式架构看作是六边形架构的一个极端。
6.4 过渡到函数式架构和基于输出的测试
Transitioning to functional architecture and outputbased testing
In this section, we’ll take a sample application and refactor it toward functional architecture. You’ll see two refactoring stages:
在这一节中,我们将采取一个示例应用程序,并将其重构为函数式架构。你会看到两个重构阶段:
Moving from using an out-of-process dependency to using mocks
从使用进程外的依赖关系转向使用 mocks
Moving from using mocks to using functional architecture
从使用 mocks 到使用函数式架构
The transition affects test code, too! We’ll refactor state-based and communication-based tests to the output-based style of unit testing. Before starting the refactoring, let’s review the sample project and tests covering it.
这一转变也会影响测试代码!我们将重构基于状态和交互的测试,使之成为基于输出的单元测试风格。在开始重构之前,让我们先回顾一下示例项目及其相关测试。
6.4.1 介绍一个审计系统
Introducing an audit system
The sample project is an audit system that keeps track of all visitors in an organization. It uses flat text files as underlying storage with the structure shown in figure 6.11. The system appends the visitor’s name and the time of their visit to the end of the most recent file. When the maximum number of entries per file is reached, a new file with an incremented index is created.
该示例项目是一个审计系统,它记录了一个组织中所有的访问者。它使用扁平文本文件作为底层存储,其结构如图 6.11 所示。该系统将访问者的名字和访问时间附加到最近的文件的末尾。当达到每个文件的最大条目数时,就会创建一个带有递增索引的新文件。
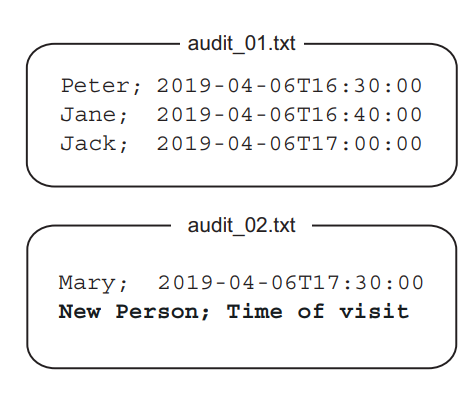
Figure 6.11 The audit system stores information about visitors in text files with a specific format. When the maximum number of entries per file is reached, the system creates a new file. 图 6.11 审计系统在具有特定格式的文本文件中存储关于访问者的信息。 当达到每个文件的最大条目数时,系统会创建一个新的文件。
The following listing shows the initial version of the system.
下面的列表显示了系统的初始版本。
Listing 6.8 Initial implementation of the audit system 清单 6.8 审计系统的初始实现
1 | public class AuditManager |
The code might look a bit large, but it’s quite simple. AuditManager is the main class in the application. Its constructor accepts the maximum number of entries per file and the working directory as configuration parameters. The only public method in the class is AddRecord, which does all the work of the audit system:
这段代码可能看起来有点大,但其实很简单。AuditManager 是应用程序中的主类。它的构造函数接受每个文件的最大条目数和工作目录作为配置参数。该类中唯一的公共方法是 AddRecord,它完成审计系统的所有工作:
Retrieves a full list of files from the working directory
从工作目录中检索完整的文件列表
Sorts them by index (all filenames follow the same pattern:
audit_{index}.txt [for example, audit_1.txt])按索引对它们进行排序(所有的文件名都遵循相同的模式:audit_{index}.txt [例如,audit_1.txt])
If there are no audit files yet, creates a first one with a single record
如果还没有审计文件,则创建第一个带有单一记录的审计文件
If there are audit files, gets the most recent one and either appends the new record to it or creates a new file, depending on whether the number of entries in that file has reached the limit
如果有审计文件,则获取最新的审计文件,并将新的记录附加到该文件中,或者创建一个新的文件,这取决于该文件中的条目数是否达到限制。
The AuditManager class is hard to test as-is, because it’s tightly coupled to the filesystem. Before the test, you’d need to put files in the right place, and after the test finishes, you’d read those files, check their contents, and clear them out (figure 6.12).
AuditManager 类很难按原样测试,因为它与文件系统紧密耦合。在测试之前,你需要把文件放在正确的地方,而在测试结束后,你要读取这些文件,检查它们的内容,并把它们清除掉(图6.12)。
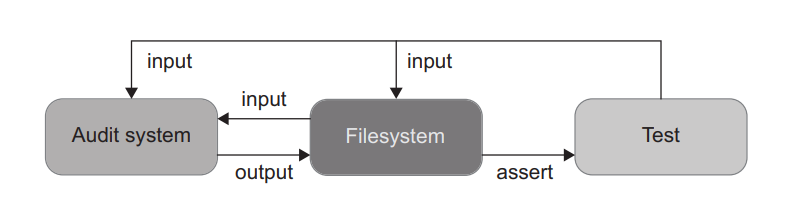
Figure 6.12 Tests covering the initial version of the audit system would have to work directly with the filesystem. 图 6.12 覆盖审计系统初始版本的测试将不得不直接与文件系统一起工作。
You won’t be able to parallelize such tests—at least, not without additional effort that would significantly increase maintenance costs. The bottleneck is the filesystem: it’s a shared dependency through which tests can interfere with each other’s execution flow.
你不可能将这样的测试并行化–至少,不付出额外的努力,就会大大增加维护成本。瓶颈是文件系统:它是一个共享的依赖关系,通过它,测试可以干扰彼此的执行流程。
The filesystem also makes the tests slow. Maintainability suffers, too, because you have to make sure the working directory exists and is accessible to tests—both on your local machine and on the build server. Table 6.2 sums up the scoring.
文件系统也使测试变得缓慢。可维护性也受到影响,因为你必须确保工作目录的存在,并且可以被测试访问–在你的本地机器和构建服务器上。表 6.2 总结了得分情况。
Table 6.2 The initial version of the audit system scores badly on two out of the four attributes of a good test.
表 6.2 初始版本的审计系统在好的测试的四个属性中的两个方面得分很低。
| Initial version | |
|---|---|
| Protection against regressions 防止回归 | Good |
| Resistance to refactoring 抵御重构 | Good |
| Fast feedback 快速反馈 | Bad |
| Maintainability 可维护性 | Bad |
By the way, tests working directly with the filesystem don’t fit the definition of a unit test. They don’t comply with the second and the third attributes of a unit test, thereby falling into the category of integration tests (see chapter 2 for more details):
顺便说一下,直接使用文件系统的测试并不符合单元测试的定义。它们不符合单元测试的第二和第三属性,因此属于集成测试的范畴(更多细节见第二章):
- A unit test verifies a single unit of behavior, 单元测试验证的是单一的行为单元、
- Does it quickly, 迅速完成、
- And does it in isolation from other tests. 并与其他测试隔离开来。
6.4.2 使用 mocks 将测试与文件系统分离
Using mocks to decouple tests from the filesystem
The usual solution to the problem of tightly coupled tests is to mock the filesystem. You can extract all operations on files into a separate class (IFileSystem) and inject that class into AuditManager via the constructor. The tests will then mock this class and capture the writes the audit system do to the files (figure 6.13).
通常解决紧密耦合的测试问题的方法是模拟文件系统。你可以将所有对文件的操作提取到一个单独的类(IFileSystem),并通过构造函数将该类注入 AuditManager。然后,测试将模拟这个类,并捕获审计系统对文件的写入操作(图6.13)。
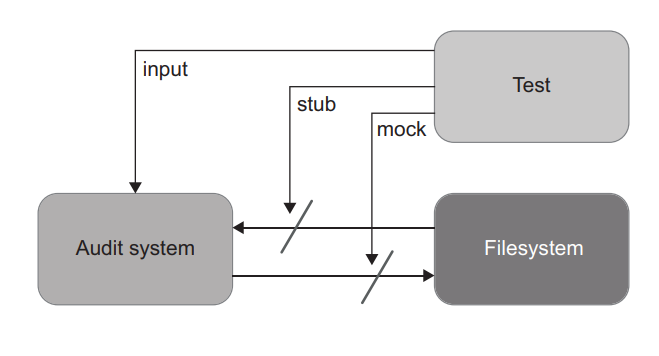
Figure 6.13 Tests can mock the filesystem and capture the writes the audit system makes to the files. 图 6.13 测试可以模拟文件系统并捕获审计系统对文件的写入。
The following listing shows how the filesystem is injected into AuditManager.
下面的列表显示了文件系统是如何被注入 AuditManager 的。
1 | public class AuditManager |
And next is the AddRecord method.
而接下来是 AddRecord 方法。
Listing 6.10 Using the new IFileSystem interface 清单 6.10 使用新的 IFileSystem 接口
1 | public void AddRecord(string visitorName, DateTime timeOfVisit) |
In listing 6.10, IFileSystem is a new custom interface that encapsulates the work with the filesystem:
在清单 6.10 中,IFileSystem 是一个新的自定义接口,它封装了文件系统的工作:
1 | public interface IFileSystem |
Now that AuditManager is decoupled from the filesystem, the shared dependency is gone, and tests can execute independently from each other. Here’s one such test.
现在,AuditManager 与文件系统解耦,共享依赖关系消失,测试可以独立执行。下面就是这样一个测试。
Listing 6.11 Checking the audit system’s behavior using a mock 清单 6.11 使用 mock 检查审计系统的行为
1 | [] |
This test verifies that when the number of entries in the current file reaches the limit (3, in this example), a new file with a single audit entry is created. Note that this is a legitimate use of mocks. The application creates files that are visible to end users (assuming that those users use another program to read the files, be it specialized software or a simple notepad.exe). Therefore, communications with the filesystem and the side effects of these communications (that is, the changes in files) are part of the application’s observable behavior. As you may remember from chapter 5, that’s the only legitimate use case for mocking.
该测试验证了当当前文件中的条目数达到限制(本例中为 3)时,会创建一个包含单个审计条目的新文件。请注意,这是对模拟的合法使用。应用程序创建的文件对最终用户是可见的(假设这些用户使用其他程序读取文件,无论是专业软件还是简单的 notepad.exe)。因此,与文件系统的交互以及这些交互的副作用(即文件的更改)都是应用程序可观察行为的一部分。正如第 5 章所述,这是模拟的唯一合法用例。
This alternative implementation is an improvement over the initial version. Since tests no longer access the filesystem, they execute faster. And because you don’t need to look after the filesystem to keep the tests happy, the maintenance costs are also reduced. Protection against regressions and resistance to refactoring didn’t suffer from the refactoring either. Table 6.3 shows the differences between the two versions.
与最初版本相比,这个替代实现有所改进。由于测试不再访问文件系统,因此执行速度更快。而且,由于不需要为了让测试顺利进行而维护文件系统,维护成本也降低了。防止回归和抵御重构也没有受到重构的影响。表 6.3 显示了两个版本之间的差异。
Table 6.3 The version with mocks compared to the initial version of the audit system 表 6.3 带模拟的版本与审计系统初始版本的比较
| Initial version | With mocks | |
|---|---|---|
| Protection against regressions 防止回归 | Good | Good |
| Resistance to refactoring 抵御重构 | Good | Good |
| Fast feedback 快速反馈 | Bad | Good |
| Maintainability 可维护性 | Bad | Moderate |
We can still do better, though. The test in listing 6.11 contains convoluted setups, which is less than ideal in terms of maintenance costs. Mocking libraries try their best to be helpful, but the resulting tests are still not as readable as those that rely on plain input and output.
不过,我们还可以做得更好。清单 6.11 中的测试包含了复杂的设置,就维护成本而言,这并不理想。模拟库会尽力提供帮助,但测试结果的可读性仍然不如那些依靠简单输入和输出的测试。
6.4.3 重构至函数式架构
Refactoring toward functional architecture
Instead of hiding side effects behind an interface and injecting that interface into AuditManager, you can move those side effects out of the class entirely. AuditManager is then only responsible for making a decision about what to do with the files. A new class, Persister, acts on that decision and applies updates to the filesystem (figure 6.14)
与其将副作用隐藏在接口后面并将该接口注入 AuditManager,不如将这些副作用完全移出该类。这样,AuditManager 只负责决定如何处理文件。一个新类 Persister 将根据该决策采取行动,并对文件系统进行更新(图 6.14)
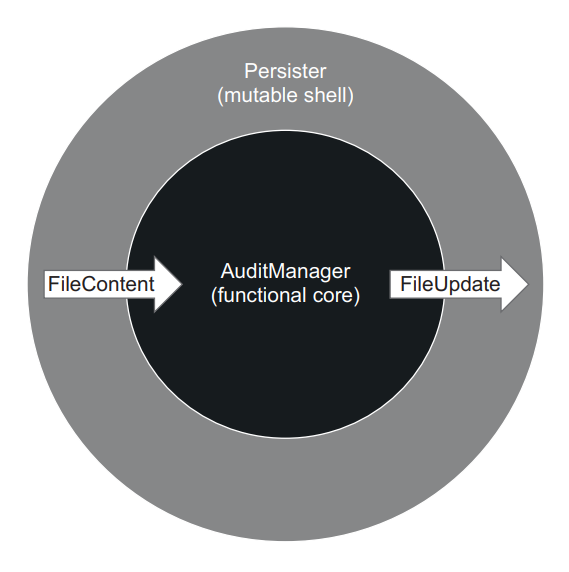
Figure 6.14 Persister and AuditManager form the functional architecture. Persister gathers files and their contents from the working directory, feeds them to AuditManager, and then converts the return value into changes in the filesystem. 图 6.14 Persister 和 AuditManager 构成了函数式架构。Persister 从工作目录中收集文件及其内容,并将其输入 AuditManager,然后将返回值转换为文件系统中的变化。
Persister in this scenario acts as a mutable shell, while AuditManager becomes a functional (immutable) core. The following listing shows AuditManager after the refactoring.
在这种情况下,Persister 是一个可变的外壳,而 AuditManager 则是一个功能(不可变)核心。下面的清单显示了重构后的 AuditManager。
Listing 6.12 The AuditManager class after refactoring 清单 6.12 重构后的 AuditManager 类
1 | public class AuditManager |
Instead of the working directory path, AuditManager now accepts an array of FileContent. This class includes everything AuditManager needs to know about the filesystem to make a decision:
AuditManager 现在接受 FileContent 数组,而不是工作目录路径。该类包含 AuditManager 在做出决定时需要了解的有关文件系统的所有信息:
1 | public class FileContent |
And, instead of mutating files in the working directory, AuditManager now returns an instruction for the side effect it would like to perform:
现在,AuditManager 不再更改工作目录中的文件,而是返回一条它希望执行的副作用指令:
1 | public class FileUpdate |
The following listing shows the Persister class.
下面的列表显示了 Persister 类。
Listing 6.13 The mutable shell acting on AuditManager’s decision 清单 6.13 根据 AuditManager 的决定操作的可变外壳
1 | public class Persister |
Notice how trivial this class is. All it does is read content from the working directory and apply updates it receives from AuditManager back to that working directory. It has no branching (no if statements); all the complexity resides in the AuditManager class. This is the separation between business logic and side effects in action.
请注意,这个类是多么简单。它所做的只是从工作目录中读取内容,并将从 AuditManager 收到的更新应用回工作目录。它没有分支(没有 if 语句);所有的复杂性都存在于 AuditManager 类中。这就是业务逻辑和副作用之间的分离。
To maintain such a separation, you need to keep the interface of FileContent and FileUpdate as close as possible to that of the framework’s built-in file-interaction commands. All the parsing and preparation should be done in the functional core, so that the code outside of that core remains trivial. For example, if .NET didn’t contain the built-in File.ReadAllLines() method, which returns the file content as an array of lines, and only has File.ReadAllText(), which returns a single string, you’d need to replace the Lines property in FileContent with a string too and do the parsing in AuditManager:
为了保持这种分离,您需要让 FileContent 和 FileUpdate 的接口尽可能接近框架内置文件交互命令的接口。所有的解析和准备工作都应在功能核心中完成,这样核心外的代码就可以保持简单。例如,如果 .NET 不包含内置的 File.ReadAllLines() 方法(该方法以行数组的形式返回文件内容),而只有 File.ReadAllText()(该方法返回单个字符串),您就需要将 FileContent 中的 Lines 属性也替换为字符串,然后在 AuditManager 中进行解析:
1 | public class FileContent |
To glue AuditManager and Persister together, you need another class: an application service in the hexagonal architecture taxonomy, as shown in the following listing
要将 AuditManager 和 Persister 粘合在一起,还需要另一个类:六边形架构分类中的应用服务,如下表所示
1 | public class ApplicationService |
Along with gluing the functional core together with the mutable shell, the application service also provides an entry point to the system for external clients (figure 6.15). With this implementation, it becomes easy to check the audit system’s behavior. All tests now boil down to supplying a hypothetical state of the working directory and verifying the decision AuditManager makes.
除了将功能核心与可变外壳粘合在一起,应用服务还为外部客户提供了一个进入系统的入口(图 6.15)。有了这种实现方式,检查审计系统的行为就变得很容易了。现在,所有的测试都归结为提供工作目录的假设状态并验证 AuditManager 所作出的决策。
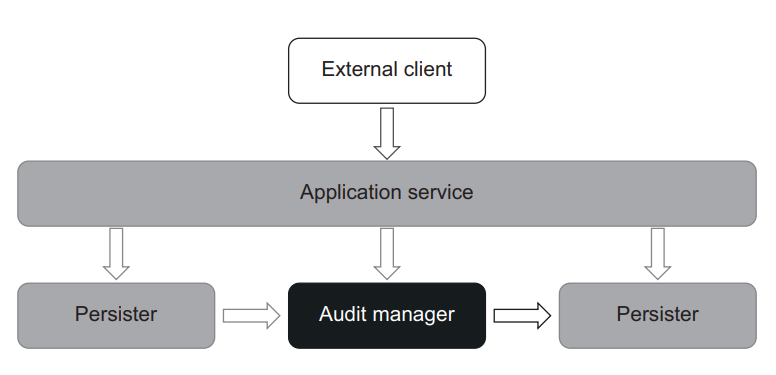
Figure 6.15 ApplicationService glues the functional core (AuditManager) and the mutable shell (Persister) together and provides an entry point for external clients. In the hexagonal architecture taxonomy, ApplicationService and Persister are part of the application services layer, while AuditManager belongs to the domain model.
图 6.15 ApplicationService 将功能核心(AuditManager)和可变外壳(Persister)粘合在一起,并为外部客户提供了一个入口点。在六边形架构分类法中,ApplicationService 和 Persister 属于应用服务层,而 AuditManager 则属于领域模型。
1 | [] |
This test retains the improvement the test with mocks made over the initial version (fast feedback) but also further improves on the maintainability metric. There’s no need for complex mock setups anymore, only plain inputs and outputs, which helps the test’s readability a lot. Table 6.4 compares the output-based test with the initial version and the version with mocks.
该测试保留了使用模拟的测试比初始版本所做的改进(快速反馈),同时还进一步提高了可维护性指标。不再需要复杂的模拟设置,只需要简单的输入和输出,这大大提高了测试的可读性。表 6.4 比较了基于输出的测试与初始版本和带有模拟的版本。
Table 6.4 The output-based test compared to the previous two versions 表 6.4 基于输出的测试与前两个版本的比较
| Initial version | With mocks | Output-baseed | |
|---|---|---|---|
| Protection against regressions 防止回归 | Good | Good | Good |
| Resistance to refactoring 抵御重构 | Good | Good | Good |
| Fast feedback 快速反馈 | Bad | Good | Good |
| Maintainability 可维护性 | Bad | Moderate | Good |
Notice that the instructions generated by a functional core are always a value or a set of values. Two instances of such a value are interchangeable as long as their contents match. You can take advantage of this fact and improve test readability even further by turning FileUpdate into a value object. To do that in .NET, you need to either convert the class into a struct or define custom equality members. That will give you comparison by value, as opposed to the comparison by reference, which is the default behavior for classes in C#. Comparison by value also allows you to compress the two assertions from listing 6.15 into one:
请注意,功能核心生成的指令总是一个值或一组值。只要内容匹配,这种值的两个实例就可以互换。您可以利用这一事实,将 FileUpdate 转换为值对象,从而进一步提高测试的可读性。要在 .NET 中做到这一点,您需要将该类转换为结构体或定义自定义相等成员。这样就可以通过值进行比较,而不是通过引用进行比较,后者是 C# 中类的默认行为。通过值比较还可以将清单 6.15 中的两个断言压缩为一个:
1 | Assert.Equal( |
Or, using Fluent Assertions, 或者,使用流畅的断言
1 | update.Should().Be( |
6.4.4 期待进一步发展
Looking forward to further developments
Let’s step back for a minute and look at further developments that could be done in our sample project. The audit system I showed you is quite simple and contains only three branches:
让我们退后一步,看看我们的示例项目还能做些什么。我向大家展示的审计系统非常简单,只包含三个分支:
- Creating a new file in case of an empty working directory 在工作目录为空的情况下创建新文件
- Appending a new record to an existing file 在现有文件中添加新记录
- Creating another file when the number of entries in the current file exceeds the limit 当当前文件中的条目数超过限制时创建另一个文件
Also, there’s only one use case: addition of a new entry to the audit log. What if there were another use case, such as deleting all mentions of a particular visitor? And what if the system needed to do validations (say, for the maximum length of the visitor’s name)?
此外,只有一种用例:向审计日志添加新条目。如果还有其他用例,比如删除所有关于某个访客的记录呢?如果系统需要进行验证(例如,验证访客姓名的最大长度)呢?
Deleting all mentions of a particular visitor could potentially affect several files, so the new method would need to return multiple file instructions:
删除某个游客的所有提及可能会影响多个文件,因此新方法需要返回多个文件指令:
1 | public FileUpdate[] DeleteAllMentions( |
Furthermore, business people might require that you not keep empty files in the working directory. If the deleted entry was the last entry in an audit file, you would need to remove that file altogether. To implement this requirement, you could rename FileUpdate to FileAction and introduce an additional ActionType enum field to indicate whether it was an update or a deletion.
此外,业务人员可能会要求你不要在工作目录中保留空文件。如果删除的条目是审计文件中的最后一个条目,则需要完全删除该文件。为了实现这一要求,您可以将 FileUpdate 更名为 FileAction,并引入一个额外的 ActionType 枚举字段来表示是更新还是删除。
Error handling also becomes simpler and more explicit with functional architecture. You could embed errors into the method’s signature, either in the FileUpdate class or as a separate component:
采用函数式架构后,错误处理也变得更简单、更明确。您可以在 FileUpdate 类中或作为一个单独的组件,将错误嵌入方法的签名中:
1 | public (FileUpdate update, Error error) AddRecord( |
The application service would then check for this error. If it was there, the service wouldn’t pass the update instruction to the persister, instead propagating an error message to the user.
然后,应用程序服务将检查该错误。如果有,服务将不会把更新指令传递给持久化器,而是向用户发送一条错误信息。
6.5 了解函数式架构的缺点
Understanding the drawbacks of functional architecture
Unfortunately, functional architecture isn’t always attainable. And even when it is, the maintainability benefits are often offset by a performance impact and increase in the size of the code base. In this section, we’ll explore the costs and the trade-offs attached to functional architecture.
遗憾的是,函数式架构并不总是可以实现的。即使可以实现,可维护性方面的优势往往也会被性能影响和代码量增加所抵消。在本节中,我们将探讨函数式架构的代价和权衡。
6.5.1 函数式架构的适用性
Applicability of functional architecture
Functional architecture worked for our audit system because this system could gather all the inputs up front, before making a decision. Often, though, the execution flow is less straightforward. You might need to query additional data from an out-of-process dependency, based on an intermediate result of the decision-making process.
函数式架构之所以适用于我们的审计系统,是因为该系统可以在做出决策前收集所有输入。但通常情况下,执行流程并不那么简单。您可能需要根据决策流程的中间结果,从流程外的依赖关系中查询其他数据。
Here’s an example. Let’s say the audit system needs to check the visitor’s access level if the number of times they have visited during the last 24 hours exceeds some threshold. And let’s also assume that all visitors’ access levels are stored in a database. You can’t pass an IDatabase instance to AuditManager like this:
下面是一个例子。假设审计系统需要检查访问者的访问级别,如果他们在过去 24 小时内的访问次数超过了某个阈值。我们还假设所有访客的访问级别都存储在数据库中。您不能像这样向 AuditManager 传递一个 IDatabase 实例:
1 | public FileUpdate AddRecord( |
Such an instance would introduce a hidden input to the AddRecord() method. This method would, therefore, cease to be a mathematical function (figure 6.16), which means you would no longer be able to apply output-based testing.
这样的实例将为 AddRecord() 方法引入一个隐藏输入。因此,该方法将不再是一个数学函数(图 6.16),这意味着您将无法再应用基于输出的测试。
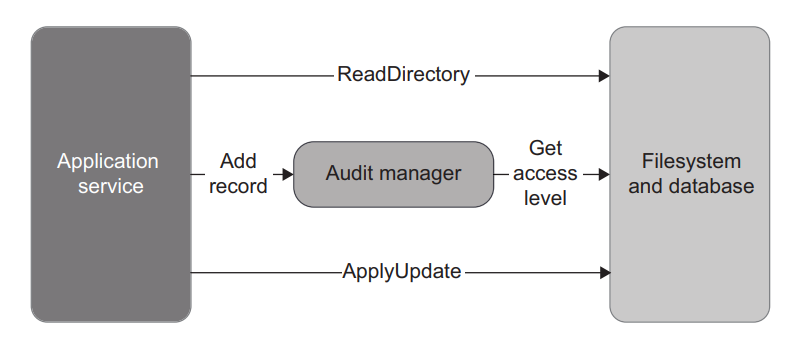
Figure 6.16 A dependency on the database introduces a hidden input to AuditManager. Such a class is no longer purely functional, and the whole application no longer follows the functional architecture. 图 6.16 对数据库的依赖为 AuditManager 引入了一个隐藏输入。这样的类就不再是纯粹的功能类,整个应用程序也不再遵循函数式架构。
There are two solutions in such a situation:
在这种情况下,有两种解决方案:
- You can gather the visitor’s access level in the application service up front, along with the directory content. 可以事先在应用服务中收集访问者的访问级别以及目录内容。
- You can introduce a new method such as IsAccessLevelCheckRequired() in AuditManager. The application service would call this method before AddRecord(), and if it returned true, the service would get the access level from the database and pass it to AddRecord(). 可以在 AuditManager 中引入一个新方法,如 IsAccessLevelCheckRequired()。应用服务将在 AddRecord() 之前调用该方法,如果返回 true,服务将从数据库中获取访问级别并将其传递给 AddRecord()。
Both approaches have drawbacks. The first one concedes performance—it unconditionally queries the database, even in cases when the access level is not required. But this approach keeps the separation of business logic and communication with external systems fully intact: all decision-making resides in AuditManager as before. The second approach concedes a degree of that separation for performance gains: the decision as to whether to call the database now goes to the application service, not AuditManager.
这两种方法都有缺点。第一种方法会影响性能–即使在不需要访问级别的情况下,它也会无条件地查询数据库。但这种方法完全保持了业务逻辑和与外部系统通信的分离:所有决策都像以前一样在 AuditManager 中进行。第二种方法为了提高性能,在一定程度上放弃了这种分离:现在,是否调用数据库的决策权归应用服务,而不是 AuditManager。
Note that, unlike these two options, making the domain model (AuditManager) depend on the database isn’t a good idea. I’ll explain more about keeping the balance between performance and separation of concerns in the next two chapters.
请注意,与这两种方案不同,让领域模型(AuditManager)依赖于数据库并不是一个好主意。在接下来的两章中,我将详细介绍如何在性能和关注点分离之间保持平衡。
Collaborators vs. values 协作者与值
You may have noticed that AuditManager’s AddRecord() method has a dependency that’s not present in its signature: the _maxEntriesPerFile field. The audit manager refers to this field to make a decision to either append an existing audit file or create a new one.
您可能已经注意到,AuditManager 的 AddRecord() 方法有一个签名中没有的依赖项:_maxEntriesPerFile 字段。审计管理器会参考该字段来决定是附加现有审计文件还是创建新文件。
Although this dependency isn’t present among the method’s arguments, it’s not hidden. It can be derived from the class’s constructor signature. And because the _maxEntriesPerFile field is immutable, it stays the same between the class instantiation and the call to AddRecord(). In other words, that field is a value.
虽然该方法的参数中没有这个依赖关系,但它并不是隐藏的。它可以从类的构造函数签名中推导出来。由于 _maxEntriesPerFile 字段是不可变的,因此它在类实例化和调用 AddRecord() 之间保持不变。换句话说,该字段是一个值。
The situation with the IDatabase dependency is different because it’s a collaborator, not a value like _maxEntriesPerFile. As you may remember from chapter 2, a collaborator is a dependency that is one or the other of the following: IDatabase
依赖关系的情况则不同,因为它是一个协作器,而不是像 _maxEntriesPerFile 这样的值。正如你在第 2 章中所记得的,合作者是一种依赖关系,它具有以下两种特性中的一种或另一种:
- Mutable (allows for modification of its state) 可变(允许修改其状态)
- A proxy to data that is not yet in memory (a shared dependency) 尚未存在于内存中的数据的代理(共享依赖关系)
The IDatabase instance falls into the second category and, therefore, is a collaborator. It requires an additional call to an out-of-process dependency and thus precludes the use of output-based testing.
IDatabase 实例属于第二类,因此是合作者。它需要额外调用进程外依赖项,因此不能使用基于输出的测试。
NOTE
A class from the functional core should work not with a collaborator, but with the product of its work, a value.
功能核心中的类不应与合作者一起工作,而应与它的工作成果(值)一起工作。
6.5.2 性能缺陷
Performance drawbacks
The performance impact on the system as a whole is a common argument against functional architecture. Note that it’s not the performance of tests that suffers. The output-based tests we ended up with work as fast as the tests with mocks. It’s that the system itself now has to do more calls to out-of-process dependencies and becomes less performant. The initial version of the audit system didn’t read all files from the working directory, and neither did the version with mocks. But the final version does in order to comply with the read-decide-act approach.
对整个系统性能的影响是反对函数式架构的一个常见理由。请注意,受影响的并不是测试的性能。我们最终使用的基于输出的测试与使用模拟的测试一样快。而是系统本身现在需要调用更多的进程外依赖项,从而降低了性能。审计系统的最初版本并不读取工作目录中的所有文件,使用模拟的版本也是如此。但最终版本却读取了所有文件,以符合 “读取-决定-执行 “的方法。
The choice between a functional architecture and a more traditional one is a trade-off between performance and code maintainability (both production and test code). In some systems where the performance impact is not as noticeable, it’s better to go with functional architecture for additional gains in maintainability. In others, you might need to make the opposite choice. There’s no one-size-fits-all solution.
在函数式架构和更传统的架构之间做出选择,是对性能和代码可维护性(包括生产代码和测试代码)的权衡。在某些对性能影响不明显的系统中,最好采用函数式架构,以获得更多的可维护性收益。而在其他系统中,您可能需要做出相反的选择。没有放之四海而皆准的解决方案。
6.5.3 增加代码库大小
Increase in the code base size
The same is true for the size of the code base. Functional architecture requires a clear separation between the functional (immutable) core and the mutable shell. This necessitates additional coding initially, although it ultimately results in reduced code complexity and gains in maintainability.
代码库的大小也是如此。函数式架构要求明确区分功能(不可变)核心和可变外壳。虽然最终会降低代码的复杂性并提高可维护性,但最初仍需要额外的编码工作。
Not all projects exhibit a high enough degree of complexity to justify such an initial investment, though. Some code bases aren’t that significant from a business perspective or are just plain too simple. It doesn’t make sense to use functional architecture in such projects because the initial investment will never pay off. Always apply functional architecture strategically, taking into account the complexity and importance of your system.
不过,并非所有项目的复杂程度都足以证明这种初始投资的合理性。从业务角度来看,有些代码库并不重要,或者过于简单。在这样的项目中使用函数式架构是没有意义的,因为初始投资永远不会有回报。考虑到系统的复杂性和重要性,一定要战略性地使用函数式架构。
Finally, don’t go for purity of the functional approach if that purity comes at too high a cost. In most projects, you won’t be able to make the domain model fully immutable and thus can’t rely solely on output-based tests, at least not when using an OOP language like C# or Java. In most cases, you’ll have a combination of outputbased and state-based styles, with a small mix of communication-based tests, and that’s fine. The goal of this chapter is not to incite you to transition all your tests toward the output-based style; the goal is to transition as many of them as reasonably possible. The difference is subtle but important.
最后,如果函数式方法的纯粹性代价太高,就不要追求纯粹性。在大多数项目中,你不可能让领域模型完全不可变,因此不能完全依赖基于输出的测试,至少在使用 C# 或 Java 这样的 OOP 语言时不能。在大多数情况下,你会将基于输出和基于状态的风格结合起来,再加上少量基于交互的测试,这样就可以了。本章的目的不是让你把所有测试都过渡到基于输出的风格,而是让你尽可能多地过渡到基于输出的风格。两者之间的区别很微妙,但却很重要。
总结
Summary
- Output-based testing is a style of testing where you feed an input to the SUT and check the output it produces. This style of testing assumes there are no hidden inputs or outputs, and the only result of the SUT’s work is the value it returns. 基于输出的测试是一种测试方式,即向被测试装置输入输入,并检查其产生的输出。这种测试方式假定没有隐藏的输入或输出,SUT 工作的唯一结果就是它返回的值。
- State-based testing verifies the state of the system after an operation is completed. 基于状态的测试验证操作完成后的系统状态。
- In communication-based testing, you use mocks to verify communications between the system under test and its collaborators. 在基于交互的测试中,使用模拟来验证被测系统与其合作者之间的交互。
- The classical school of unit testing prefers the state-based style over the communication-based one. The London school has the opposite preference. Both schools use output-based testing. 与基于交互的测试相比,经典的单元测试学派更倾向于基于状态的测试。伦敦学派的偏好正好相反。两派都使用基于输出的测试。
- Output-based testing produces tests of the highest quality. Such tests rarely couple to implementation details and thus are resistant to refactoring. They are also small and concise and thus are more maintainable. 基于输出的测试能产生最高质量的测试。这种测试很少涉及实现细节,因此能抵御重构。它们还小巧简洁,因此更易于维护。
- State-based testing requires extra prudence to avoid brittleness: you need to make sure you don’t expose a private state to enable unit testing. Because statebased tests tend to be larger than output-based tests, they are also less maintainable. Maintainability issues can sometimes be mitigated (but not eliminated) with the use of helper methods and value objects. 基于状态的测试需要格外谨慎,以避免脆性:你需要确保不暴露私有状态以实现单元测试。由于基于状态的测试往往比基于输出的测试更大,它们的可维护性也更差。可维护性问题有时可以通过使用辅助方法和值对象来缓解(但不能消除)。
- Communication-based testing also requires extra prudence to avoid brittleness. You should only verify communications that cross the application boundary and whose side effects are visible to the external world. Maintainability of communication-based tests is worse compared to output-based and state-based tests. Mocks tend to occupy a lot of space, and that makes tests less readable. 基于交互的测试也需要格外谨慎,以避免脆性。您应该只验证跨越应用程序边界的交互,而且其副作用对外部世界是可见的。与基于输出和状态的测试相比,基于交互的测试的可维护性较差。Mock 会占用大量空间,从而降低测试的可读性。
- Functional programming is programming with mathematical functions. 函数式编程是使用数学函数进行编程。
- A mathematical function is a function (or method) that doesn’t have any hidden inputs or outputs. Side effects and exceptions are hidden outputs. A reference to an internal or external state is a hidden input. Mathematical functions are explicit, which makes them extremely testable. 数学函数是一种没有任何隐藏输入或输出的函数(或方法)。副作用和异常是隐藏输出。对内部或外部状态的引用是隐藏输入。数学函数是显式的,因此极易测试。
- The goal of functional programming is to introduce a separation between business logic and side effects. 函数式编程的目标是引入业务逻辑与副作用之间的分离。
- Functional architecture helps achieve that separation by pushing side effects to the edges of a business operation. This approach maximizes the amount of code written in a purely functional way while minimizing code that deals with side effects. 函数式架构将副作用推向业务操作的边缘,有助于实现这种分离。这种方法可以最大限度地增加以纯函数方式编写的代码,同时最大限度地减少处理副作用的代码。
- Functional architecture divides all code into two categories: functional core and mutable shell. The functional core makes decisions. The mutable shell supplies input data to the functional core and converts decisions the core makes into side effects. 函数式架构将所有代码分为两类:功能核心和可变外壳。功能核心负责决策。可变外壳向功能核心提供输入数据,并将核心做出的决定转换为副作用。
- The difference between functional and hexagonal architectures is in their treatment of side effects. Functional architecture pushes all side effects out of the domain layer. Conversely, hexagonal architecture is fine with side effects made by the domain layer, as long as they are limited to that domain layer only. Functional architecture is hexagonal architecture taken to an extreme. 函数式架构与六边形架构的区别在于对副作用的处理。函数式架构将所有副作用都推出了领域层。相反,六边形架构则对领域层产生的副作用视而不见,只要这些副作用仅限于该领域层。函数式架构是六边形架构的一个极端。
- The choice between a functional architecture and a more traditional one is a trade-off between performance and code maintainability. Functional architecture concedes performance for maintainability gains. 在函数式架构和更传统的架构之间,我们需要在性能和代码可维护性之间做出权衡。函数式架构以牺牲性能来换取可维护性的提高。
- Not all code bases are worth converting into functional architecture. Apply functional architecture strategically. Take into account the complexity and the importance of your system. In code bases that are simple or not that important, the initial investment required for functional architecture won’t pay off. 并非所有代码库都值得转换为函数式架构。要战略性地应用函数式架构。考虑系统的复杂性和重要性。对于简单或不太重要的代码库,函数式架构所需的初始投资不会得到回报。